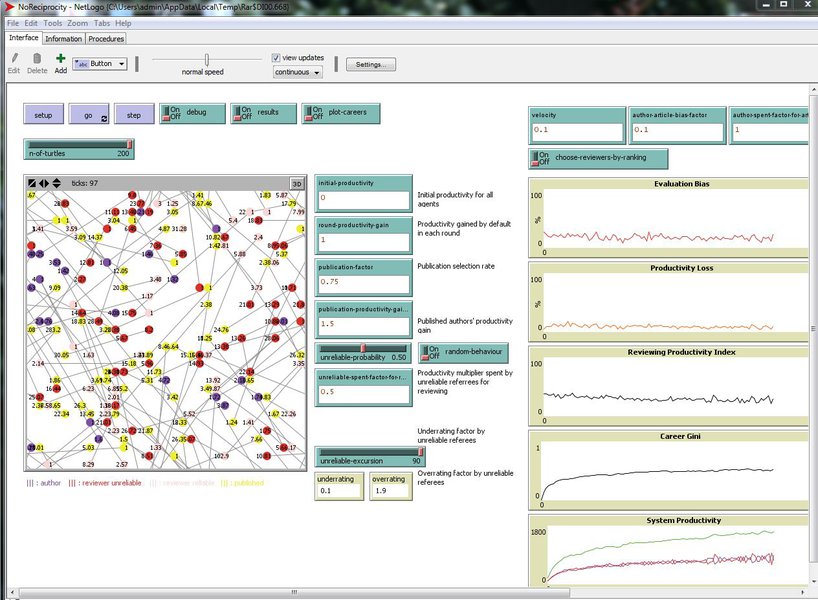
Peer Review Model 1.1.0
The model starts from a population of N scientists (N = 200) randomly selected each tick to play one of two roles: authors or referees. The task of an author is to submit an article and have it published. The task of a referee is to evaluate the quality of submissions by authors. Depending on the referees’ opinion, only the best submissions are published (i.e., those exceeding the publication rate p). Resources ae needed both to submit and review an article. With each simulation tick, agents are endowed with a fixed amount of resources f, equal for all (e.g., common access to research infrastructure and internal funds, availability of PhD. students). Then, they cumulate resources according to their publication score.
Each agent has an estimated submission quality. If published, resources are multiplied, otherwise they are lost. Referees can behave more or less reliably and so under/over rate the quality of the author submission. The chance of publication only depends on referee opinion.
The purpose is to replicate certain mechanisms of peer review (conflict between publishing and reviewing, evaluation bias, referee reliability) to understand implications of scientist behaviour for the quality and efficiency of the evaluation process.
It runs in NetLogo and supports five scenarios, where rules of behaviour of authors and referees are modified, as described in Squazzoni and Gandelli (2012), forthcoming.
Scenarios are as follows:
NoReciprocity: This file runs the the “no reciprocity” scenario, where we assumed that, when selected as referees, agents always had a random probability of behaving unreliably, which was constant over time and not influenced by past experiences. When selected as authors, agents always invested all their resources for publication, irrespectively of positive or negative past experience with their submission.
-
IndirectReciprocity: This file runs the “indirect reciprocity” scenario, where we assumed that agents, in case of previous publication, reciprocated by providing reliable evaluation in turn when selected as referees. If false, they provide unreliable reviews.
-
Fairness: This file runs the “fairness” scenario. The assumption was that if the evaluation of an author’s submission was pertinent ( = it approximated the real value of the authors’ submission), he/she was reliable the next time he/she was selected as referee; if the evaluation was no-pertinent (= it did not approximate the real value of the author’s submission), the author was unreliable the next time he/she was selected as referee.
-
SelfInterestedAuthors: This file runs the “self-interested authors” scenario, where we assumed that, when published, authors reacted positively and continued to invest all their resources for their next submission. In case of rejection, they reacted negatively and invested less in the subsequent round (i.e., only the 10% of their resources)
-
FairAuthors: This file runs the “Fair authors” scenario, where we assumed that in case of a pertinent referee evaluation received when authors, agents reinforced their confidence on the good quality of the evaluation process and continued to invest everything to send good quality submissions irrespectively of the fate of their submission. In case of non-pertinent evaluation, they invested less in the subsequent round (i.e., only the 10% of their resources) and accumulate resources for the subsequent round irrespectively of their previous publication.