About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 175 results information clear search
Agent-based tax evasion model for investigating impacts of public disclosure
Hiroyuki Sano | Published Thursday, March 14, 2024The model explores the impact of public disclosure on tax compliance among diverse agents, including individual taxpayers and a tax authority. It incorporates heterogeneous preferences and income endowments among taxpayers, captured through a utility function that considers psychic costs subtracted from expected pecuniary utility. These costs include moral, reciprocity, and stigma costs associated with norm violations, leading to variations in taxpayers’ risk attitudes and related parameters. The tax authority’s attributes, such as the frequency of random audits, penalty rate, and the choice between partial or full disclosure, remain fixed throughout the simulation. Income endowments and preference parameters are randomly assigned to taxpayers at the outset.
Taxpayers maximize their expected utility by reporting income, taking into account tax, penalty, and audit rates. They make annual decisions based on their own and their peers’ behaviors from the previous year. Taxpayers indirectly interact at the societal level through public disclosure conducted by the tax authority, exchanging tax information among peers. Each period in the simulation collects data on total reported income, average compliance rates per income group, distribution of compliance rates, counts of compliers, full evaders, partial evaders, and the numbers of taxpayers experiencing guilt and anger. The model evaluates whether public disclosure positively or negatively impacts compliance rates and quantifies this impact based on aggregated individual reporting behaviors.
How information propagation in hybrid spaces affects decision-making: using ABM to simulate Covid-19 vaccine uptake
Fuzhen Yin | Published Wednesday, March 13, 2024Abstract: The notion of physical space has long been central in geographical theories. However, the widespread adoption of information and communication technologies (ICTs) has freed human dynamics from purely physical to also relational and cyber spaces. While researchers increasingly recognize such shifts, rarely have studies examined how the information propagates in these hybrid spaces (i.e., physical, relational, and cyber). By exploring the vaccine opinion dynamics through agent-based modeling, this study is the first that combines all hybrid spaces and explores their distinct impacts on human dynamics from an individual’s perspective. Our model captures the temporal dynamics of vaccination progress with small errors (MAE=2.45). Our results suggest that all hybrid spaces are indispensable in vaccination decision making. However, in our model, most of the agents tend to give more emphasis to the information that is spread in the physical instead of other hybrid spaces. Our study not only sheds light on human dynamics research but also offers a new lens to identifying vaccinated individuals which has long been challenging in disease-spread models. Furthermore, our study also provides responses for practitioners to develop vaccination outreach policies and plan for future outbreaks.
Peer reviewed MADTOR: Model for Assessing Drug Trafficking Organizations Resilience
Deborah Manzi | Published Friday, February 23, 2024Criminal organizations operate in complex changing environments. Being flexible and dynamic allows criminal networks not only to exploit new illicit opportunities but also to react to law enforcement attempts at disruption, enhancing the persistence of these networks over time. Most studies investigating network disruption have examined organizational structures before and after the arrests of some actors but have disregarded groups’ adaptation strategies.
MADTOR simulates drug trafficking and dealing activities by organized criminal groups and their reactions to law enforcement attempts at disruption. The simulation relied on information retrieved from a detailed court order against a large-scale Italian drug trafficking organization (DTO) and from the literature.
The results showed that the higher the proportion of members arrested, the greater the challenges for DTOs, with higher rates of disrupted organizations and long-term consequences for surviving DTOs. Second, targeting members performing specific tasks had different impacts on DTO resilience: targeting traffickers resulted in the highest rates of DTO disruption, while targeting actors in charge of more redundant tasks (e.g., retailers) had smaller but significant impacts. Third, the model examined the resistance and resilience of DTOs adopting different strategies in the security/efficiency trade-off. Efficient DTOs were more resilient, outperforming secure DTOs in terms of reactions to a single, equal attempt at disruption. Conversely, secure DTOs were more resistant, displaying higher survival rates than efficient DTOs when considering the differentiated frequency and effectiveness of law enforcement interventions on DTOs having different focuses in the security/efficiency trade-off.
Overall, the model demonstrated that law enforcement interventions are often critical events for DTOs, with high rates of both first intention (i.e., DTOs directly disrupted by the intervention) and second intention (i.e., DTOs terminating their activities due to the unsustainability of the intervention’s short-term consequences) culminating in dismantlement. However, surviving DTOs always displayed a high level of resilience, with effective strategies in place to react to threatening events and to continue drug trafficking and dealing.
Peer reviewed Agent-Based Ramsey growth model with endogenous technical progress (ABRam-T)
Sarah Wolf Aida Sarai Figueroa Alvarez Malika Tokpanova | Published Wednesday, February 14, 2024 | Last modified Monday, February 19, 2024The Agent-Based Ramsey growth model is designed to analyze and test a decentralized economy composed of utility maximizing agents, with a particular focus on understanding the growth dynamics of the system. We consider farms that adopt different investment strategies based on the information available to them. The model is built upon the well-known Ramsey growth model, with the introduction of endogenous technical progress through mechanisms of learning by doing and knowledge spillovers.
How Availability Heuristic, Confirmation Bias and Fear May Drive Societal Polarisation: An Opinion Dynamics Simulation of the Case of COVID-19 Vaccination
Teng Li | Published Friday, December 22, 2023This model simulates the opinion dynamics of COVID-19 vaccination to examine especially how fears and cognitive bias contribute to the opinion polarisation and vaccination rate. In studying the opinion dynamics of COVID-19 vaccination, this model refers to the HUMAT framework (Antosz et al, 2019). Many psychological and social processes are included in the model, such as dynamical decision-making processes of information exchange and fear formation, satisfaction evaluation, preferred decision selection and dissonance reduction.
The Urban Drought Nexus Tool
Roger Cremades Muhamad Khairulbahri | Published Thursday, December 14, 2023The “Urban Drought Nexus Tool” is a system dynamics model, aiming to facilitate the co-development of climate services for cities under increasing droughts. The tool integrates multiple types of information and still can be applied to other case studies with minimal adjustments on the parameters of land use, water consumption and energy use in the water sector. The tool needs hydrological projections under climate scenarios to evaluate climatic futures, and requires the co-creation of socio-economic future scenarios with local stakeholders. Thus it is possible to provide specific information about droughts taking into account future water availability and future water consumption. Ultimately, such complex system as formed by the water-energy-land nexus can be reduced to single variables of interest, e.g. the number of events with no water available in the future and their length, so that the complexities are reduced and the results can be conveyed to society in an understandable way, including the communication of uncertainties. The tool and an explanatory guide in pdf format are included. Planned further developments include calibrating the system dynamics model with the social dynamics behind each flow with agent-based models.
Peer reviewed Yards
srailsback Emily Minor Soraida Garcia Philip Johnson | Published Thursday, November 02, 2023This is a model of plant communities in urban and suburban residential neighborhoods. These plant communities are of interest because they provide many benefits to human residents and also provide habitat for wildlife such as birds and pollinators. The model was designed to explore the social factors that create spatial patterns in biodiversity in yards and gardens. In particular, the model was originally developed to determine whether mimicry behaviors–-or neighbors copying each other’s yard design–-could produce observed spatial patterns in vegetation. Plant nurseries and socio-economic constraints were also added to the model as other potential sources of spatial patterns in plant communities.
The idea for the model was inspired by empirical patterns of spatial autocorrelation that have been observed in yard vegetation in Chicago, Illinois (USA), and other cities, where yards that are closer together are more similar than yards that are farther apart. The idea is further supported by literature that shows that people want their yards to fit into their neighborhood. Currently, the yard attribute of interest is the number of plant species, or species richness. Residents compare the richness of their yards to the richness of their neighbors’ yards. If a resident’s yard is too different from their neighbors, the resident will be unhappy and change their yard to make it more similar.
The model outputs information about the diversity and identity of plant species in each yard. This can be analyzed to look for spatial autocorrelation patterns in yard diversity and to explore relationships between mimicry behaviors, yard diversity, and larger scale diversity.
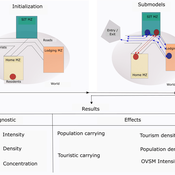
Peer reviewed ABM Overtourism Santa Marta
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.

Peer reviewed A Bayesian Nash Equilibrium (BNE)-informed ABM for pedestrian evacuation in different constricted spaces
Jiaqi Ge Yiyu Wang Alexis Comber | Published Wednesday, October 11, 2023This BNE-informed ABM ultimately aims to provide a more realistic description of complicated pedestrian behaviours especially in high-density and life-threatening situations. Bayesian Nash Equilibrium (BNE) was adopted to reproduce interactive decision-making process among rational and game-playing agents. The implementations of 3 behavioural models, which are Shortest Route (SR) model, Random Follow (RF) model, and BNE model, make it possible to simulate emergent patterns of pedestrian behaviours (e.g. herding and self-organised queuing behaviours, etc.) in emergency situations.
According to the common features of previous mass trampling accidents, a series of simulation experiments were performed in space with 3 types of barriers, which are Horizontal Corridors, Vertical Corridors, and Random Squares, standing for corridors, bottlenecks and intersections respectively, to investigate emergent behaviours of evacuees in varied constricted spatial environments. The output of this ABM has been available at https://data.mendeley.com/datasets/9v4byyvgxh/1.
Controlling the misinformation diffusion in social media by the effect of different classes of agents
Ali Khodabandeh Yalabadi | Published Thursday, October 05, 2023An agent-based framework to simulate the diffusion process of a piece of misinformation according to the SBFC model in which the fake news and its debunking compete in a social network. Considering new classes of agents, this model is closer to reality and proposed different strategies how to mitigate and control misinformation.
Displaying 10 of 175 results information clear search