Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 4 of 4 results for "Wijnand Boonstra" clear search

Peer reviewed FIBE - FIsher BEhaviour model
Nanda Wijermans Maja Schlüter Kirill Orach Wijnand Boonstra Jonas Hentati-Sundberg | Published Monday, April 20, 2020FIBE represents a simple fishery model. Fish that reproduce and fisher with different fishing styles that fish as their main source of income. The aim of the model is to reflect the different fishing behaviours as described and observed in the (Swedish) Baltic Sea fishery and explore the consequences of different approximations of human/fisher behaviour in under different environmental and managerial scenarios.
The overarching aim is to advance the incorporation and understanding of human behaviour (diversity) in fisheries research and management. In particular focusing on insights from social (fishery) science of fisher behaviour.
Peer reviewed Casting: A Bio-Inspired Method for Restructuring Machine Learning Ensembles
Colin Lynch Bryan Daniels | Published Thursday, September 18, 2025The wisdom of the crowd refers to the phenomenon in which a group of individuals, each making independent decisions, can collectively arrive at highly accurate solutions—often more accurate than any individual within the group. This principle relies heavily on independence: if individual opinions are unbiased and uncorrelated, their errors tend to cancel out when averaged, reducing overall bias. However, in real-world social networks, individuals are often influenced by their neighbors, introducing correlations between decisions. Such social influence can amplify biases, disrupting the benefits of independent voting. This trade-off between independence and interdependence has striking parallels to ensemble learning methods in machine learning. Bagging (bootstrap aggregating) improves classification performance by combining independently trained weak learners, reducing bias. Boosting, on the other hand, explicitly introduces sequential dependence among learners, where each learner focuses on correcting the errors of its predecessors. This process can reinforce biases present in the data even if it reduces variance. Here, we introduce a new meta-algorithm, casting, which captures this biological and computational trade-off. Casting forms partially connected groups (“castes”) of weak learners that are internally linked through boosting, while the castes themselves remain independent and are aggregated using bagging. This creates a continuum between full independence (i.e., bagging) and full dependence (i.e., boosting). This method allows for the testing of model capabilities across values of the hyperparameter which controls connectedness. We specifically investigate classification tasks, but the method can be used for regression tasks as well. Ultimately, casting can provide insights for how real systems contend with classification problems.
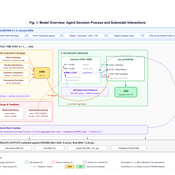
Peer reviewed Kenya ITN Agent-Based Microsimulation (2003–2024)
Wooyoung Kim Hosang Shin | Published Saturday, April 18, 2026 | Last modified Tuesday, June 16, 2026An agent-based microsimulation of insecticide-treated net (ITN) distribution and adoption in Kenya (2003–2024), integrating the Theory of Planned Behaviour, Rogers diffusion, Weibull net decay, and a GPS-based two-layer social network. 8,561 household agents calibrated via Approximate Bayesian Computation to six DHS/MIS survey waves, achieving 2.42 pp mean absolute error on Kenya-level ownership. The analysis chain supports mechanism counterfactuals and policy experiments on equity outcomes of ITN distribution strategies.

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…