About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 130 results for "Sandra H Goff" clear search
Scientific disagreements and the diagnosticity of evidence
Matteo Michelini | Published Wednesday, December 13, 2023The present model is an abstract ABM designed for theoretical exploration and hypotheses generation. Its main aim is to explore the relationship between disagreement over the diagnostic value of evidence and the formation of polarization in scientific communities.
The model represents a scientific community in which scientists aim to determine whether hypothesis H is true, and we assume that agents are in a world in which H is indeed true. To this end, scientists perform experiments, interpret data and exchange their views on how diagnostic of H the obtained evidence is. Based on how the scientists conduct the inquiry, the community may reach a correct consensus (i.e. a situation in which every scientist agrees that H is correct) or not.
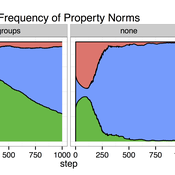
Cultural Group Selection of Sustainable Institutions
Timothy Waring Paul Smaldino Sandra H Goff | Published Wednesday, June 10, 2015 | Last modified Tuesday, August 04, 2015We develop a spatial, evolutionary model of the endogenous formation and dissolution of groups using a renewable common pool resource. We use this foundation to measure the evolutionary pressures at different organizational levels.
An agent-based model to study the effects of urban sprawl on bird distribution
Yun Ouyang | Published Tuesday, December 16, 2008 | Last modified Saturday, April 27, 2013This model was programmed for a class project, which studied the effects of urban sprawl on bird distribution. For the urban sprawl part of the model, we started from the model in (udhira, H. S., 200
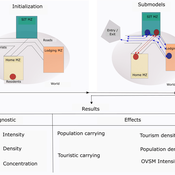
Peer reviewed ABM Overtourism Santa Marta
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.
Agent-Based Model for the Evolution of Ethnocentrism
Max Hartshorn | Published Saturday, March 24, 2012 | Last modified Saturday, April 27, 2013This is an implementation of an agent based model for the evolution of ethnocentrism. While based off a model published by Hammond and Axelrod (2006), the code has been modified to allow for a more fine-grained analysis of evolutionary dynamics.
Gunpowder battle tactics
Xavier Rubio-Campillo Jose María Cela Francesc Xavier Hernàndez | Published Wednesday, November 20, 2013 | Last modified Tuesday, November 26, 2013This model simulates the dynamics of eighteenth-century infantry battle tactics. The goal is to explore the effect of different tactics and individual traits in the dynamics of the combat.

Sea Bright, NJ Reconstruction of Hurricane Sandy
Kim McEligot | Published Saturday, March 20, 2021 This model implements a combined Protective Action Decision Model (PADM) and Protection Motivation Theory (PAM) model for human decision making regarding hazard mitigations. The model is developed and integrated into the MASON modeling framework. The ABM implements a hind-cast of Hurricane Sandy’s damage to Sea Bright, NJ and homeowner post-flood reconstruction decisions. It was validated against FEMA damage assessments and post-storm surveys (O’Neil 2017).
Mesoscopic Effects in an Agent-Based Bargaining Model in Regular Lattices
David Poza José Manuel Galán Ordax José Santos Adolfo López-Paredes | Published Thursday, February 02, 2017 | Last modified Wednesday, April 25, 2018We propose an agent-based model where a fixed finite population of tagged agents play iteratively the Nash demand game in a regular lattice. The model extends the bargaining model by Axtell, Epstein and Young.
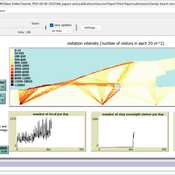
Sandy Beach Visitor Flow: An Agent-Based Model
Elham Bakhshianlamouki | Published Thursday, March 14, 2024The model is intended to simulate visitor spatial and temporal dynamics, encompassing their numbers, activities, and distribution along a coastline influenced by beach landscape design. Our primary focus is understanding how the spatial distribution of services and recreational facilities (e.g., beach width, entrance location, recreational facilities, parking availability) impacts visitation density. Our focus is not on tracking the precise visitation density but rather on estimating the areas most affected by visitor activity. This comprehension allows for assessing the diverse influences of beach layouts on spatial visitor density and, consequently, on the landscape’s biophysical characteristics (e.g., vegetation, fauna, and sediment features).
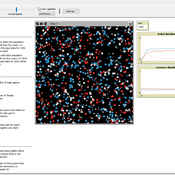
Peer reviewed Modelling the Social Complexity of Reputation and Status Dynamics
André Grow Andreas Flache | Published Wednesday, February 01, 2017 | Last modified Wednesday, January 23, 2019The purpose of this model is to illustrate the use of agent-based computational modelling in the study of the emergence of reputation and status beliefs in a population.
Displaying 10 of 130 results for "Sandra H Goff" clear search