Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1195 results for "Aad Kessler" clear search
Amazon smallholder resilience
Yue Dou | Published Monday, September 09, 2019The purpose of this agent-based model is to simulate the behaviors of small farming households in the Amazon estuary region and evaluate their resilience to external shocks with the presence of several government cash transfer programs.
An Agent-based Model of Farmland Transfer (Version 1.0.0)
Hang Xiong Peng Jiang | Published Wednesday, August 11, 2021This is model that explores how a few farmers in a Chinese village, where all farmers are smallholders originally, reach optimal farming scale by transferring in farmland from other farmers in the context of urbanization and aging.
An Agent-Based Model of Language Contact
Marco Civico | Published Tuesday, July 30, 2019This model is part of an article that discusses the adoption of a complexity theory approach to study the dynamics of language contact within multilingual communities. The model simulates the dynamics of communication within a community where a minority and a majority group coexist. The individual choice of language for communication is based on a number of simple rules derived from a review of the main literature on the topic of language contact. These rules are then combined with different variables, such as the rate of exogamy of the minority group and the presence of relevant education policies, to estimate the trends of assimilation of the minority group into the majority one. The model is validated using actually observed data from the case of Romansh speakers in the canton of Grisons, Switzerland.
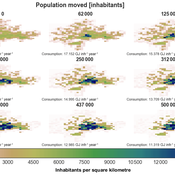
IUCM - The Integrated Urban Complexity Model
Roger Cremades Philipp S. Sommer | Published Thursday, December 14, 2023We present the Integrated Urban Complexity model (IUCm 1.0) that computes “climate-smart urban forms”, which are able to cut emissions related to energy consumption from urban mobility in half. Furthermore, we show the complex features that go beyond the normal debates about urban sprawl vs. compactness. Our results show how to reinforce fractal hierarchies and population density clusters within climate risk constraints to significantly decrease the energy consumption of urban mobility. The new model that we present aims to produce new advice about how cities can combat climate change. From a technical angle, this model is a geographical automaton, conceptually interfacing between cellular automata and spatial explicit optimisation to achieve normative sustainability goals related to low energy. See a complete user guide at https://iucm.readthedocs.io/en/latest/ .
Peer reviewed Least cost path mobility
Colin Wren Claudine Gravel-Miguel | Published Saturday, September 02, 2017 | Last modified Monday, October 04, 2021This model aims to mimic human movement on a realistic topographical surface. The agent does not have a perfect knowledge of the whole surface, but rather evaluates the best path locally, at each step, thus mimicking imperfect human behavior.
CAUS - Configurational Analysis of Urban Systems
gkdalcin | Published Sunday, December 03, 2023Hybrid model, composed of cellular automata and agents, which attempts to represent the spatial allocation of the population of Brazilian coastal cities based on the use of network analysis metrics as an indication of the attractiveness of the area.
Network structures tutorial
Tom Brughmans | Published Sunday, September 30, 2018 | Last modified Tuesday, October 02, 2018A draft model with some useful code for creating different network structures using the Netlogo NW extension. This model is used for the following tutorial:
Brughmans, T. (2018). Network structures and assembling code in Netlogo, Tutorial, https://archaeologicalnetworks.wordpress.com/resources/#structures .
Pastoralscape
Matthew Sottile | Published Tuesday, October 12, 2021Pastoralscape is a model of human agents, lifestock health and contageous disease for studying the impact of human decision making in pastoral communities within East Africa on livestock populations. It implements an event-driven agent based model in Python 3.
Will you infect me with your opinion?
Jarosław Miszczak Krzysztof Domino | Published Tuesday, March 15, 2022 | Last modified Monday, August 29, 2022This model incorporates three mechanisms shaping the dynamics of opinion formation, which mimics the dynamics of the virus spreading in the population. There are three methods of getting infected (or convinced) - direct contact, indirect contact, and contact with ``contaminated’’ elements.
An agent-based model of adaptive cycles of the spruce budworm
Julia Schindler | Published Saturday, August 18, 2012 | Last modified Saturday, April 27, 2013This is an empirically calibrated agent-based model that replicates spruce-budworm outbreaks, one of the most cited adaptive cycles reported. The adaptive-cycle metaphor by L. H. Gunderson and C. S. Holling posits the cross-case existence of repeating cycles of growth, conservation, collapse, and renewal in many complex systems, triggered by loss of resilience. This model is one of the first agent-based models of such cycles, with the novelty that adaptive cycles are not defined by system- […]
Displaying 10 of 1195 results for "Aad Kessler" clear search