About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 2 of 2 results sociology of science clear search
Open Peer Review Model
Federico Bianchi | Published Monday, May 24, 2021This is an agent-based model of a population of scientists alternatively authoring or reviewing manuscripts submitted to a scholarly journal for peer review. Peer-review evaluation can be either ‘confidential’, i.e. the identity of authors and reviewers is not disclosed, or ‘open’, i.e. authors’ identity is disclosed to reviewers. The quality of the submitted manuscripts vary according to their authors’ resources, which vary according to the number of publications. Reviewers can assess the assigned manuscript’s quality either reliably of unreliably according to varying behavioural assumptions, i.e. direct/indirect reciprocation of past outcome as authors, or deference towards higher-status authors.
Peer Review Game
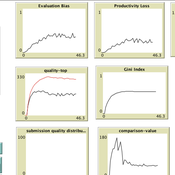
Giangiacomo Bravo Flaminio Squazzoni Francisco Grimaldo Federico Bianchi | Published Monday, April 30, 2018NetLogo software for the Peer Review Game model. It represents a population of scientists endowed with a proportion of a fixed pool of resources. At each step scientists decide how to allocate their resources between submitting manuscripts and reviewing others’ submissions. Quality of submissions and reviews depend on the amount of allocated resources and biased perception of submissions’ quality. Scientists can behave according to different allocation strategies by simply reacting to the outcome of their previous submission process or comparing their outcome with published papers’ quality. Overall bias of selected submissions and quality of published papers are computed at each step.