Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1284 results Sort by: Recently modified clear search
Industrial Cooperation and the Hydrogen Transition
Amineh Ghorbani Renske van 't Veer Emre Ates Zofia Lukszo | Published Tuesday, September 23, 2025An Agent Based Model that explores the deployment of hydrogen among a regional industrial cluster in the Netherlands, consisting of 15 companies. The companies seek to decarbonize by replacing their natural gas by hydrogen.
The model integrates technical characteristics as well as company motivations to transition to hydrogen. The baseline model only considers individual investments where company can locally produce hydrogen. If they reach the backbone threshold, companies can also consider buying hydrogen through a connection to the national hydrogen network. The second scenario considers that companies can participate in a joint investment to get an electrolyzer to locally produce the hydrogen.
Two experiments look at the impact of the sectoral configuration and at the impact of subsidy conditions on the region’s hydrogen transition
Incentives for data sharing
Flaminio Squazzoni Federico Bianchi Thomas Klebel Tony Ross-Hellauer | Published Thursday, October 02, 2025Although beneficial to scientific development, data sharing is still uncommon in many research areas. Various organisations, including funding agencies that endorse open science, aim to increase its uptake. However, estimating the large-scale implications of different policy interventions on data sharing by funding agencies, especially in the context of intense competition among academics, is difficult empirically. Here, we built an agent-based model to simulate the effect of different funding schemes (i.e., highly competitive large grants vs. distributive small grants), and varying intensity of incentives for data sharing on the uptake of data sharing by academic teams strategically adapting to the context.
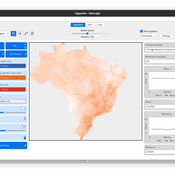
LogoClim: WorldClim in NetLogo
Daniel Vartanian Leandro Garcia Aline Martins de Carvalho Aline | Published Thursday, July 03, 2025 | Last modified Tuesday, September 16, 2025LogoClim is a NetLogo model for simulating and visualizing global climate conditions. It allows researchers to integrate high-resolution climate data into agent-based models, supporting reproducible research in ecology, agriculture, environmental sciences, and other fields that rely on climate data.
The model utilizes raster data to represent climate variables such as temperature and precipitation over time. It incorporates historical data (1951-2024) and future climate projections (2021-2100) derived from global climate models under various Shared Socioeconomic Pathways (SSPs, O’Neill et al., 2017). All climate inputs come from WorldClim 2.1, a widely used source of high-resolution, interpolated climate datasets based on weather station observations worldwide (Fick & Hijmans, 2017).
LogoClim follows the FAIR Principles for Research Software (Barker et al., 2022) and is openly available on the CoMSES Network and GitHub. See the Logônia model for an example of its integration into a full NetLogo simulation.
Logônia: Plant Growth Response Model in NetLogo
Leandro Garcia Daniel Vartanian Aline | Published Saturday, September 13, 2025 | Last modified Tuesday, September 16, 2025Logônia is a NetLogo model that simulates the growth response of a fictional plant, logônia, under different climatic conditions. The model uses climate data from WorldClim 2.1 and demonstrates how to integrate the LogoClim model through the LevelSpace extension.
Logônia follows the FAIR Principles for Research Software (Barker et al., 2022) and is openly available on the CoMSES Network and GitHub.
GODS: Gossip-Oriented Dilemma Simulator
Jan Majewski | Published Wednesday, September 04, 2024 | Last modified Monday, September 29, 2025Model of influence of access to social information spread via social network on decisions in a two-person game.
Political Participation
Didier Ruedin | Published Saturday, April 12, 2014 | Last modified Sunday, September 28, 2025Implementation of Milbrath’s (1965) model of political participation. Individual participation is determined by stimuli from the political environment, interpersonal interaction, as well as individual characteristics.

The conditional defector strategy can violate the most crucial supporting mechanisms of cooperation.
Ahmed Ibrahim | Published Tuesday, June 07, 2022 | Last modified Sunday, September 28, 2025Cooperation is essential for all domains of life. Yet, ironically, it is intrinsically vulnerable to exploitation by cheats. Hence, an explanatory necessity spurs many evolutionary biologists to search for mechanisms that could support cooperation. In general, cooperation can emerge and be maintained when cooperators are sufficiently interacting with themselves. This communication provides a kind of assortment and reciprocity. The most crucial and common mechanisms to achieve that task are kin selection, spatial structure, and enforcement (punishment). Here, we used agent-based simulation models to investigate these pivotal mechanisms against conditional defector strategies. We concluded that the latter could easily violate the former and take over the population. This surprising outcome may urge us to rethink the evolution of cooperation, as it illustrates that maintaining cooperation may be more difficult than previously thought. Moreover, empirical applications may support these theoretical findings, such as invading the cooperator population of pathogens by genetically engineered conditional defectors, which could be a potential therapy for many incurable diseases.
Peer reviewed Casting: A Bio-Inspired Method for Restructuring Machine Learning Ensembles
Colin Lynch Bryan Daniels | Published Thursday, September 18, 2025The wisdom of the crowd refers to the phenomenon in which a group of individuals, each making independent decisions, can collectively arrive at highly accurate solutions—often more accurate than any individual within the group. This principle relies heavily on independence: if individual opinions are unbiased and uncorrelated, their errors tend to cancel out when averaged, reducing overall bias. However, in real-world social networks, individuals are often influenced by their neighbors, introducing correlations between decisions. Such social influence can amplify biases, disrupting the benefits of independent voting. This trade-off between independence and interdependence has striking parallels to ensemble learning methods in machine learning. Bagging (bootstrap aggregating) improves classification performance by combining independently trained weak learners, reducing bias. Boosting, on the other hand, explicitly introduces sequential dependence among learners, where each learner focuses on correcting the errors of its predecessors. This process can reinforce biases present in the data even if it reduces variance. Here, we introduce a new meta-algorithm, casting, which captures this biological and computational trade-off. Casting forms partially connected groups (“castes”) of weak learners that are internally linked through boosting, while the castes themselves remain independent and are aggregated using bagging. This creates a continuum between full independence (i.e., bagging) and full dependence (i.e., boosting). This method allows for the testing of model capabilities across values of the hyperparameter which controls connectedness. We specifically investigate classification tasks, but the method can be used for regression tasks as well. Ultimately, casting can provide insights for how real systems contend with classification problems.
Peer reviewed Agent-Based Ramsey growth model with Brown and Green capital (ABRam-BG)
Sarah Wolf Aida Sarai Figueroa Alvarez | Published Monday, December 09, 2024The purpose of the ABRam-BG model is to study belief dynamics as a potential driver of green (growth) transitions and illustrate their dynamics in a closed, decentralized economy populated by utility maximizing agents with an environmental attitude. The model is built using the ABRam-T model (for model visit: https://doi.org/10.25937/ep45-k084) and introduces two types of capital – green (low carbon intensity) and brown (high carbon intensity) – with their respective technological progress levels. ABRam-BG simulates a green transition as an emergent phenomenon resulting from well-known opinion dynamics along the economic process.
Netlogo model ` Effect of Network Homophily and Partisanship on Social Media to “Oil Spill” Polarizations’
takuya nagura | Published Saturday, September 13, 2025This model was utilized for the simulation in the paper titled Effect of Network Homophily and Partisanship on Social Media to “Oil Spill” Polarizations. It allows you to examine whether oil spill polarization occurs through people’s communication under various conditions.
・Choose the network construction conditions you’d like to examine from the “rewire-style” chooser box.
・Select the desired strength of partisanship from the “partisanlevel” chooser box. You can also set the strength manually in the code tab.
・You can set the number of dynamic topics using the “number-of-topics” slider.
・Use the “divers-of-opinion” slider to set the number of preference types for each dynamic topic.
…
Displaying 10 of 1284 results Sort by: Recently modified clear search