Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 44 results exploration clear search
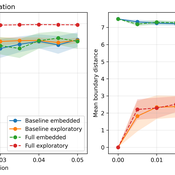
From Boundary Crossings to Global Connectivity: A Minimal Mechanism in Structured Agent-Based Landscapes
Fabio Nelli | Published Sunday, May 17, 2026This repository contains the Python implementation of an agent-based model investigating how localized boundary-crossing dynamics generate large-scale connectivity in structured multi-attractor landscapes.
Agents evolve in a continuous two-dimensional environment composed of attractor basins. A fraction of agents exhibits exploratory higher-mobility dynamics, while the remaining agents remain locally constrained. The model analyzes how localized configurational transitions accumulate into transition networks that progressively integrate the explored state space.
The repository includes:
…
A simulation model for Dublin city
umesh7lowe | Published Friday, April 10, 2026An agent-based model of urban travel behaviour in Dublin, Ireland, built in NetLogo and empirically grounded in 2016 travel survey data. Each agent represents a Dublin resident initialised with real socio-demographic attributes — including age, gender, household size and car ownership, income, driving licence status, and access to local amenities — alongside observed trip characteristics such as distance, travel time, and trip type (work, shopping, leisure).
At each time step, agents choose between four transport modes (car, public transport, cycling, and walking) across short, medium, and long trips. Mode choice is governed by a preference vector that weighs personal need satisfaction against social influence from neighbouring agents reflecting consumat framework. Satisfaction evolves dynamically based on cost (incorporating Irish motor tax bands and per-km operating rates), travel time, and trip-type suitability, with an uncertainty parameter capturing variability in perceived utility over time.
The model tracks aggregate modal shares and total CO2 emission at each tick, enabling exploration of how policy interventions — such as fuel taxation, public transport pricing, or active travel incentives — might shift the city’s travel demand profile over 100 simulated days.
Peer reviewed Gradient Descent Simulation
Ilyes Azouani | Published Wednesday, March 18, 2026 | Last modified Monday, May 25, 2026This model visualizes gradient descent optimization - the fundamental algorithm used to train neural networks and other machine learning models. Agents represent different optimization algorithms searching for the minimum of a loss landscape (the “error surface” that ML models try to minimize during training).
The model demonstrates how different optimizer types (SGD, Momentum with different parameters) behave on various loss landscapes, from simple bowls to the notoriously difficult Rosenbrock “banana valley” function. This helps build intuition about why certain optimization algorithms work better than others for different problem geometries.
HOW IT WORKS
…
Selene ABM Suite
ihctdy-f | Published Sunday, January 11, 2026Project Selene ABM Suite
Agent-Based Scenario Exploration for Consortium Cooperation Dynamics
Version: 2.1 (Revised)
Date: January 2026
Status: Exploratory Analysis Tool
An agent-based model of the journey of victim/survivors through local authority domestic abuse support services in the UK
Bruce Edmonds | Published Monday, July 28, 2025This model played a small part in the UK government’s review of the working of local authority implementation of the Domestic Abuse legislation. The model explicitly represents victim-survivor families as they: (a) try to contact the local DA support system, (b) are triaged by the system and (if there is space) allocated to safe temporary accomodation (c) recieve support services from this position and (d) eventually move on to more permenant accomodation. The purpose of the model was to understand some possible ways in which the implementation of DA Duty, might be frustrated in practice, the identification of gaps in the evidence base and to inform the developing Theory of Change. The key measures used for assessing outcomes in the model were the number of families helped and the services that were delivered to them. The exploration was grounded for in two archetypal cases: that of a relatively immature system for the delivery of DA services and a more mature one (based on actual local authority cases, but not based on any single one). See the official report under associated publications for a summary of results.
Urban Teacher Lifecycle and Mobility
Yevgeny Patarakin | Published Wednesday, July 23, 2025This agent-based model simulates the lifecycle, movement, and satisfaction of teachers within an urban educational system composed of multiple universities and schools. Each teacher agent transitions through several possible roles: newcomer, university student, unemployed graduate, and employed teacher. Teachers’ pathways are shaped by spatial configuration, institutional capacities, individual characteristics, and dynamic interactions with schools and universities. Universities are assigned spatial locations with a controllable level of centralization and are characterized by academic ratings, capacity, and alumni records. Schools are distributed throughout the city, each with a limited number of vacancies, hiring requirements, and offered salaries. Teachers apply to universities based on the alignment of their personal academic profiles with institutional ratings, pursue studies, and upon graduation become candidates for employment at schools.
The employment process is driven by a decentralized matching of teacher expectations and school offers, taking into account factors such as salary, proximity, and peer similarity. Teachers’ satisfaction evolves over time, reflecting both institutional characteristics and the composition of their colleagues; low satisfaction may prompt teachers to transfer between schools within their mobility radius. Mortality and teacher attrition further shape workforce dynamics, leading to continuous recruitment of newcomers to maintain a stable population. The model tracks university reputation through the academic performance and number of alumni, and visualizes key metrics including teacher status distribution, school staffing, university alumni counts, and overall satisfaction. This structure enables the exploration of policy interventions, hiring and training strategies, and the impact of spatial and institutional design on the allocation, retention, and happiness of urban educational staff.
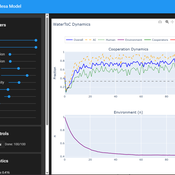
Tragedy of the Commons with Environmental Feedback: A Model of Human-AI Socio-Environmental Water Dilemma
Ivana Malcic Luka Waronig Andrew Crossley | Published Saturday, July 05, 2025 | Last modified Sunday, July 06, 2025This project is an interactive agent-based model simulating consumption of a shared, renewable resource using a game-theoretic framework with environmental feedback. The primary function of this model was to test how resource-use among AI and human agents degrades the environment, and to explore the socio-environmental feedback loops that lead to complex emergent system dynamics. We implemented a classic game theoretic matrix which decides agents´ strategies, and added a feedback loop which switches between strategies in pristine vs degraded environments. This leads to cooperation in bad environments, and defection in good ones.
Despite this use, it can be applicable for a variety of other scenarios including simulating climate disasters, environmental sensitivity to resource consumption, or influence of environmental degradation to agent behaviour.
The ABM was inspired by the Weitz et. al. (2016, https://pubmed.ncbi.nlm.nih.gov/27830651/) use of environmental feedback in their paper, as well as the Demographic Prisoner’s Dilemma on a Grid model (https://mesa.readthedocs.io/stable/examples/advanced/pd_grid.html#demographic-prisoner-s-dilemma-on-a-grid). The main innovation is the added environmental feedback with local resource replenishment.
Beyond its theoretical insights into coevolutionary dynamics, it serves as a versatile tool with several practical applications. For urban planners and policymakers, the model can function as a ”digital sandbox” for testing the impacts of locating high-consumption industrial agents, such as data centers, in proximity to residential communities. It allows for the exploration of different urban densities, and the evaluation of policy interventions—such as taxes on defection or subsidies for cooperation—by directly modifying the agents’ resource consumptions to observe effects on resource health. Furthermore, the model provides a framework for assessing the resilience of such socio-environmental systems to external shocks.
…
Peer reviewed The Indus Village's Weather model: procedural generation of daily weather
Andreas Angourakis | Published Tuesday, May 13, 2025Overview
The Weather model is a procedural generation model designed to create realistic daily weather data for socioecological simulations. It generates synthetic weather time series for solar radiation, temperature, and precipitation using algorithms based on sinusoidal and double logistic functions. The model incorporates stochastic variation to mimic unpredictable weather patterns and aims to provide realistic yet flexible weather inputs for exploring diverse climate scenarios.
The Weather model can be used independently or integrated into larger models, providing realistic weather patterns without extensive coding or data collection. It can be customized to meet specific requirements, enabling users to gain a better understanding of the underlying mechanisms and have greater confidence in their applications.
…
Agent-Based Model for Multiple Team Membership (ABMMTM)
Andrew Collins | Published Thursday, April 03, 2025The Agent-Based Model for Multiple Team Membership (ABMMTM) simulates design teams searching for viable design solutions, for a large design project that requires multiple design teams that are working simultaneously, under different organizational structures; specifically, the impact of multiple team membership (MTM). The key mechanism under study is how individual agent-level decision-making impacts macro-level project performance, specifically, wage cost. Each agent follows a stochastic learning approach, akin to simulated annealing or reinforcement learning, where they iteratively explore potential design solutions. The agent evaluates new solutions based on a random-walk exploration, accepting improvements while rejecting inferior designs. This iterative process simulates real-world problem-solving dynamics where designers refine solutions based on feedback.
As a proof-of-concept demonstration of assessing the macro-level effects of MTM in organizational design, we developed this agent-based simulation model which was used in a simulation experiment. The scenario is a system design project involving multiple interdependent teams of engineering designers. In this scenario, the required system design is split into three separate but interdependent systems, e.g., the design of a satellite could (trivially) be split into three components: power source, control system, and communication systems; each of three design team is in charge of a design of one of these components. A design team is responsible for ensuring its proposed component’s design meets the design requirement; they are not responsible for the design requirements of the other components. If the design of a given component does not affect the design requirements of the other components, we call this the uncoupled scenario; otherwise, it is a coupled scenario.
MeReDiem : Fallow Land Simulations to examine the conditions of sustainable village livelihood
Etienne DELAY Paul Chapron Mathieu | Published Monday, January 20, 2025 | Last modified Tuesday, January 21, 2025The MeReDiem model aims to simulate the effect of socio-agricultural practices of farmers and pastors on the food sustainability and soil fertility of a serrer village, in Senegal. The model is a central part of a companion modeling and exploration approach, described in a paper, currently under review)
The village population is composed of families (kitchens). Kitchens cultivate their land parcels to feed their members, aiming for food security at the family level. On a global level , the village tries to preserve the community fallow land as long as possible.
Kitchens sizes vary depending on the kitchens food production, births and migration when food is insufficient.
…
Displaying 10 of 44 results exploration clear search