About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 207 results for "Martin Loidl" clear search

Bicycle model
Gudrun Wallentin Dana Kaziyeva Martin Loidl | Published Thursday, January 10, 2019 | Last modified Monday, February 22, 2021The purpose of the model is to generate the spatio-temporal distribution of bicycle traffic flows at a regional scale level. Disaggregated results are computed for each network segment with the minute time step. The human decision-making is governed by probabilistic rules derived from the mobility survey.
Pedestrian model
Gudrun Wallentin Dana Kaziyeva Martin Loidl Petra Stutz | Published Monday, August 07, 2023The model generates disaggregated traffic flows of pedestrians, simulating their daily mobility behaviour represented as probabilistic rules. Various parameters of physical infrastructure and travel behaviour can be altered and tested. This allows predicting potential shifts in traffic dynamics in a simulated setting. Moreover, assumptions in decision-making processes are general for mid-sized cities and can be applied to similar areas.
Together with the model files, there is the ODD protocol with the detailed description of model’s structure. Check the associated publication for results and evaluation of the model.
Installation
Download GAMA-platform (GAMA1.8.2 with JDK version) from https://gama-platform.github.io/. The platform requires a minimum of 4 GB of RAM.
…
Peer reviewed ABM Overtourism Santa Marta
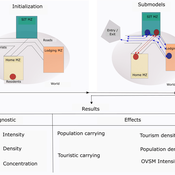
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.
Change and Senescence
André Martins | Published Tuesday, November 10, 2020Agers and non-agers agent compete over a spatial landscape. When two agents occupy the same grid, who will survive is decided by a random draw where chances of survival are proportional to fitness. Agents have offspring each time step who are born at a distance b from the parent agent and the offpring inherits their genetic fitness plus a random term. Genetic fitness decreases with time, representing environmental change but effective non-inheritable fitness can increase as animals learn and get bigger.

Peer reviewed Credit and debt market of low-income families
Márton Gosztonyi | Published Tuesday, December 12, 2023 | Last modified Friday, January 19, 2024The purpose of the Credit and debt market of low-income families model is to help the user examine how the financial market of low-income families works.
The model is calibrated based on real-time data which was collected in a small disadvantaged village in Hungary it contains 159 households’ social network and attributes data.
The simulation models the households’ money liquidity, expenses and revenue structures as well as the formal and informal loan institutions based on their network connections. The model forms an intertwined system integrated in the families’ local socioeconomic context through which families handle financial crises and overcome their livelihood challenges from one month to another.
The simulation-based on the abstract model of low-income families’ financial survival system at the bottom of the pyramid, which was described in following the papers:
…
Peninsula_Iberica 1.0
Carolina Cucart-Mora Sergi Lozano Javier Fernández-López De Pablo | Published Friday, November 04, 2016 | Last modified Monday, November 27, 2017This model was build to explore the bio-cultural interaction between AMH and Neanderthals during the Middle to Upper Paleolithic Transition in the Iberian Peninsula
Multi-agent model of the spread of climate change denial
Kalina Maria Piskorska Martin Takáč | Published Monday, March 03, 2025This NetLogo model simulates the spread of climate change beliefs within a population of individuals. Each believer has an initial belief level, which changes over time due to interactions with other individuals and exposure to media. The aim of the model is to identify possible methods for reducing climate change denial.
Soy2Grow-ABM-V1
Siavash Farahbakhsh | Published Monday, January 20, 2025The Soy2Grow ABM aims to simulate the adoption of soybean production in Flanders, Belgium. The model primarily considers two types of agents as farmers: 1) arable and 2) dairy farmers. Each farmer, based on its type, assesses the feasibility of adopting soybean cultivation. The feasibility assessment depends on many interrelated factors, including price, production costs, yield, disease, drought (i.e., environmental stress), social pressure, group formations, learning and skills, risk-taking, subsidies, target profit margins, tolerance to bad experiences, etc. Moreover, after adopting soybean production, agents will reassess their performance. If their performance is unsatisfactory, an agent may opt out of soy production. Therefore, one of the main outcomes to look for in the model is the number of adopters over time.
The main agents are farmers. Generally, factors influencing farmers’ decision-making are divided into seven main areas: 1) external environmental factors, 2) cooperation and learning (with slight differences depending on whether they are arable or dairy farmers), 3) crop-specific factors, 4) economics, 5) support frameworks, 6) behavioral factors, and 7) the role of mobile toasters (applicable only to dairy farmers).
Moreover, factors not only influence decision-making but also interact with each other. Specifically, external environmental factors (i.e., stress) will result in lower yield and quality (protein content). The reducing effect, identified during participatory workshops, can reach 50 %. Skills can grow and improve yield; however, their growth has a limit and follows different learning curves depending on how individualistic a farmer is. During participatory workshops, it was identified that, contrary to cooperative farmers, individualistic farmers may learn faster and reach their limits more quickly. Furthermore, subsidies directly affect revenues and profit margins; however, their impact may disappear when they are removed. In the case of dairy farmers, mobile toasters play an important role, adding toasting and processing costs to those producing soy for their animal feed consumption.
Last but not least, behavioral factors directly influence the final adoption decision. For example, high risk-taking farmers may adopt faster, whereas more conservative farmers may wait for their neighbors to adopt first. Farmers may evaluate their success based on their own targets and may also consider other crops rather than soy.
Viability analysis of a population submitted to floods
Sophie Martin | Published Wednesday, September 22, 2021This model computes the guaranteed viability kernel of a model describing the evolution of a population submitted to successive floods.
The population is described by its wealth and its adaptation rate to floods, the control are information campaigns that have a cost but increase the adaptation rate and the expected successive floods belong to given set defined by the maximal high and the minimal time between two floods.
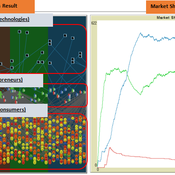
The simulation on the study of the optimal business strategy with the interaction between technologies and consumers.
sej-yoo | Published Monday, June 27, 2022 | Last modified Monday, July 04, 2022HOW IT WORKS
This model consists of three agents, and each agent type operates per business theories as below.
a. New technologies(Tech): It evolves per sustaining or disruptive technology trajectory with the constraint of project management triangle (Scope, Time, Quality, and Cost).
b. Entrepreneurs(Entre): It builds up the solution by combining Tech components per its own strategy (Exploration, Exploitation, or Ambidex).
c. Consumer(Consumer): It selects the solution per its own preference due to Diffusion of innovation theory (Innovators, Early Adopters, Early Majority, Late Majority, Laggards)
…
Displaying 10 of 207 results for "Martin Loidl" clear search