About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 73 results for "Alessandro K Cerutti" clear search

Alternative scenarios of green consumption in Italy: an empirically grounded model.
Giangiacomo Bravo Elena Vallino Alessandro K Cerutti Maria Beatrice Pairotti | Published Thursday, March 28, 2013 | Last modified Saturday, April 27, 2013We provide a full description of the model following the ODD protocol (Grimm et al. 2010) in the attached document. The model is developed in NetLogo 5.0 (Wilenski 1999).
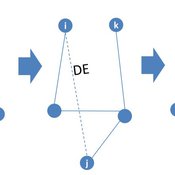
Adaptive model of a consumer advice network
Peng Shao | Published Monday, May 14, 2018In the consumer advice network, users with connections can interact with each other, and the network topology will change during the opinion interaction. When the opinion distance from i to j is greater than the confidence threshold, the two consumers cannot exchange opinions, and the link between them will disconnect with probability DE. Then, a link from node i to node k is established with probability CE and node i learning opinion from node k.
Social Closure and the Evolution of Cooperation via Indirect Reciprocity
Károly Takács Simone Righi | Published Saturday, June 09, 2018 | Last modified Saturday, June 09, 2018Righi S., Takacs K., Social Closure and the Evolution of Cooperation via Indirect Reciprocity, Resubmitted after Revisions to Scientific Reports
Tiebout sorting
Marco Janssen | Published Thursday, January 24, 2019This Netlogo replication of Kollman, K., J.H. Miller and S.E. Page (1997) Political Institutions and Sorting in a Tiebout Model, American Economic Review 87(5): 977-992. The model consists of of citizens who can vote for partie and move to other jurisdictions if they expect their preferences are better served. Parties adjust their positions to increase their share in the elections.
MERCURY extension: transport-cost
Tom Brughmans | Published Monday, July 23, 2018This is extended version of the MERCRUY model (Brughmans 2015) incorporates a ‘transport-cost’ variable, and is otherwise unchanged. This extended model is described in this publication: Brughmans, T., 2019. Evaluating the potential of computational modelling for informing debates on Roman economic integration, in: Verboven, K., Poblome, J. (Eds.), Structural Determinants in the Roman World.
Brughmans, T., 2015. MERCURY: an ABM of tableware trade in the Roman East. CoMSES Comput. Model Libr. URL https://www.comses.net/codebases/4347/releases/1.1.0/
Peer reviewed Virus Transmission with Super-spreaders
J M Applegate | Published Saturday, September 11, 2021A curious aspect of the Covid-19 pandemic is the clustering of outbreaks. Evidence suggests that 80\% of people who contract the virus are infected by only 19% of infected individuals, and that the majority of infected individuals faile to infect another person. Thus, the dispersion of a contagion, $k$, may be of more use in understanding the spread of Covid-19 than the reproduction number, R0.
The Virus Transmission with Super-spreaders model, written in NetLogo, is an adaptation of the canonical Virus Transmission on a Network model and allows the exploration of various mitigation protocols such as testing and quarantines with both homogenous transmission and heterogenous transmission.
The model consists of a population of individuals arranged in a network, where both population and network degree are tunable. At the start of the simulation, a subset of the population is initially infected. As the model runs, infected individuals will infect neighboring susceptible individuals according to either homogenous or heterogenous transmission, where heterogenous transmission models super-spreaders. In this case, k is described as the percentage of super-spreaders in the population and the differing transmission rates for super-spreaders and non super-spreaders. Infected individuals either recover, at which point they become resistant to infection, or die. Testing regimes cause discovered infected individuals to quarantine for a period of time.
MTC_Model_Pilditch&Madsen
Toby Pilditch | Published Friday, October 09, 2020Micro-targeted vs stochastic political campaigning agent-based model simulation. Written by Toby D. Pilditch (University of Oxford, University College London), in collaboration with Jens K. Madsen (University of Oxford, London School of Economics)
The purpose of the model is to explore the various impacts on voting intention among a population sample, when both stochastic (traditional) and Micto-targeted campaigns (MTCs) are in play. There are several stages of the model: initialization (setup), campaigning (active running protocols) and vote-casting (end of simulation). The campaigning stage consists of update cycles in which “voters” are targeted and “persuaded” - updating their beliefs in the campaign candidate / policies.
Social identity approach in a data-driven Axelrod model
alejandrodinkelberg | Published Thursday, July 28, 2022Simulations based on the Axelrod model and extensions to inspect the volatility of the features over time (AXELROD MODEL & Agreement threshold & two model variations based on the Social identity approach)
The Axelrod model is used to predict the number of changes per feature in comparison to the datasets and is used to compare different model variations and their performance.
Input: Real data
…
Replication of ECEC model: Environmental Feedback and the Evolution of Cooperation
Pierre Bommel | Published Tuesday, April 05, 2011 | Last modified Saturday, April 27, 2013The model, presented here, is a re-implementation of the Pepper and Smuts’ model : - Pepper, J.W. and B.B. Smuts. 2000. “The evolution of cooperation in an ecological context: an agent-based model”. Pp. 45-76 in T.A. Kohler and G.J. Gumerman, eds. Dynamics of human and primate societies: agent-based modeling of social and spatial processes. Oxford University Press, Oxford. - Pepper, J.W. and B.B. Smuts. 2002. “Assortment through Environmental Feedback”. American Naturalist, 160: 205-213 […]
High Standards Enhance Inequality in Idealized Labor Markets
Károly Takács | Published Tuesday, March 20, 2018Takács, K. and Squazzoni, F. 2015. High Standards Enhance Inequality in Idealized Labor Markets. Journal of Artificial Societies and Social Simulation, 18(4), 2, http://jasss.soc.surrey.ac.uk/18/4/2.html
We built a simple model of an idealized labor market, in which there is no objective difference in average quality between groups and hiring decisions are not biased in favor of any particular group. Our results show that inequality in employment emerges necessarily also in such idealized situations due to the limited supply of high quality individuals and asymmetric information. Inequalities are exacerbated when employers have high standards and keep only the best workers in house. We found that ambitious workers get higher quality jobs even if ambition does not correlate or even negatively correlates with internal quality. Our findings help to corroborate empirical findings on higher employment discrepancies in high rather than low status jobs.
Displaying 10 of 73 results for "Alessandro K Cerutti" clear search