Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 217 results population clear search

Peer reviewed Social Consequences of Past Compound Events - Laacher See Eruption
Kevin Su Brennen Bouwmeester | Published Monday, May 17, 2021Resilience of humans in the Upper Paleolithic could provide insights in how to defend against today’s environmental threats. Approximately 13,000 years ago, the Laacher See volcano located in present-day western Germany erupted cataclysmically. Archaeological evidence suggests that this is eruption – potentially against the background of a prolonged cold spell – led to considerable culture change, especially at some distance from the eruption (Riede, 2017). Spatially differentiated and ecologically mediated effects on contemporary social networks as well as social transmission effects mediated by demographic changes in the eruption’s wake have been proposed as factors that together may have led to, in particular, the loss of complex technologies such as the bow-and-arrow (Riede, 2014; Riede, 2009).
This model looks at the impact of the interaction between climate change trajectory and an extreme event, such as the Laacher See eruption, on the generational development of hunter-gatherer bands. Historic data is used to model the distribution and population dynamics of hunter-gatherer bands during these circumstances.
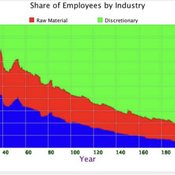
Peer reviewed A Macroeconomic Model of a Closed Economy
Ian Stuart | Published Saturday, May 08, 2021 | Last modified Wednesday, June 23, 2021This model/program presents a “three industry model” that may be particularly useful for macroeconomic simulations. The main purpose of this program is to demonstrate a mechanism in which the relative share of labor shifts between industries.
Care has been taken so that it is written in a self-documenting way so that it may be useful to anyone that might build from it or use it as an example.
This model is not intended to match a specific economy (and is not calibrated to do so) but its particular minimalist implementation may be useful for future research/development.
…
AIforGoodSimulator - Modeling Covid-19 Spread and Potential Interventions in Refugee Camps
Shyaam Ramkumar Woi Sok Oh | Published Thursday, March 18, 2021The Netlogo model is a conceptualization of the Moria refugee camp, capturing the household demographics of refugees in the camp, a theoretical friendship network based on values, and an abstraction of their daily activities. The model then simulates how Covid-19 could spread through the camp if one refugee is exposed to the virus, utilizing transmission probabilities and the stages of disease progression of Covid-19 from susceptible to exposed to asymptomatic / symptomatic to mild / severe to recovered from literature. The model also incorporates various interventions - PPE, lockdown, isolation of symptomatic refugees - to analyze how they could mitigate the spread of the virus through the camp.
Human Environment Estuarine Systems Investigator
Andrew Allison | Published Friday, February 26, 2021This model simulates the form and function of an idealised estuary with associated barrier-spit complex on the north east coast of New Zealand’s North Island (from Bream Bay to central Bay of Plenty) during the years 2010 - 2050 CE. It combines variables from social, ecological and geomorphic systems to simulate potential directions of change in shallow coastal systems in response to external forcing from land use, climate, pollution, population density, demographics, values and beliefs. The estuary is over 1000Ha, making it a large estuary according to Hume et al. (2007) - there are 12 large estuaries in the Auckland region alone (Suyadi et al., 2019). The model was developed as part of Andrew Allison’s PhD Thesis in Geography from the School of Environment and Institute of Marine Science, University of Auckland, New Zealand. The model setup allows for alteration of geomorphic, ecological and social variables to suit the specific conditions found in various estuaries along the north east coast of New Zealand’s North Island.
This model is not a predictive or forecasting model. It is designed to investigate potential directions of change in complex shallow coastal systems. This model must not be used for any purpose other than as a heuristic to facilitate researcher and stakeholder learning and for developing system understanding (as per Allison et al., 2018).
Hybrid agent-based methodology for testing response protocols
Fernando Sancho Caparrini | Published Wednesday, February 03, 2021In recent years we have seen multiple incidents with a large number of people injured and killed by one or more armed attackers. Since this type of violence is difficult to predict, detecting threats as early as possible allows to generate early warnings and reduce response time. In this context, any tool to check and compare different action protocols can be a further step in the direction of saving lives. Our proposal combines features from continuous and discrete models to obtain the best of both worlds in order to simulate large and crowded spaces where complex behavior individuals interact. With this proposal we aim to provide a tool for testing different security protocols under several emergency scenarios, where spaces, hazards, and population can be customized. Finally, we use a proof of concept implementation of this model to test specific security protocols under emergency situations for real spaces. Specifically, we test how providing some users of a university college with an app that informs about the type and characteristics of the ongoing hazard, affects in the safety performance.

Introducing two extensions of Schelling's segregation model
Andreas Flache Carlos A. de Matos Fernandes | Published Monday, January 25, 2021Schelling famously proposed an extremely simple but highly illustrative social mechanism to understand how strong ethnic segregation could arise in a world where individuals do not necessarily want it. Schelling’s simple computational model is the starting point for our extensions in which we build upon Wilensky’s original NetLogo implementation of this model. Our two NetLogo models can be best studied while reading our chapter “Agent-based Computational Models” (Flache and de Matos Fernandes, 2021). In the chapter, we propose 10 best practices to elucidate how agent-based models are a unique method for providing and analyzing formally precise, and empirically plausible mechanistic explanations of puzzling social phenomena, such as segregation, in the social world. Our chapter addresses in particular analytical sociologists who are new to ABMs.
In the first model (SegregationExtended), we build on Wilensky’s implementation of Schelling’s model which is available in NetLogo library (Wilensky, 1997). We considerably extend this model, allowing in particular to include larger neighborhoods and a population with four groups roughly resembling the ethnic composition of a contemporary large U.S. city. Further features added concern the possibility to include random noise, and the addition of a number of new outcome measures tuned to highlight macro-level implications of the segregation dynamics for different groups in the agent society.
In SegregationDiscreteChoice, we further modify the model incorporating in particular three new features: 1) heterogeneous preferences roughly based on empirical research categorizing agents into low, medium, and highly tolerant within each of the ethnic subgroups of the population, 2) we drop global thresholds (%-similar-wanted) and introduce instead a continuous individual-level single-peaked preference function for agents’ ideal neighborhood composition, and 3) we use a discrete choice model according to which agents probabilistically decide whether to move to a vacant spot or stay in the current spot by comparing the attractiveness of both locations based on the individual preference functions.
…
While the world’s total urban population continues to grow, not all cities are witnessing such growth, some are actually shrinking. This shrinkage causes several problems to emerge including population loss, economic depression, vacant properties and the contraction of housing markets. Such problems challenge efforts to make cities sustainable. While there is a growing body of work on study shrinking cities, few explore such a phenomenon from the bottom up using dynamic computational models. To overcome this issue this paper presents an spatially explicit agent-based model stylized on the Detroit Tri-county area, an area witnessing shrinkage. Specifically, the model demonstrates how through the buying and selling of houses can lead to urban shrinkage from the bottom up. The model results indicate that along with the lower level housing transactions being captured, the aggregated level market conditions relating to urban shrinkage are also captured (i.e., the contraction of housing markets). As such, the paper demonstrates the potential of simulation to explore urban shrinkage and potentially offers a means to test polices to achieve urban sustainability.
PopComp
Andre Costopoulos | Published Thursday, December 10, 2020PopComp by Andre Costopoulos 2020
[email protected]
Licence: DWYWWI (Do whatever you want with it)
I use Netlogo to build a simple environmental change and population expansion and diffusion model. Patches have a carrying capacity and can host two kinds of populations (APop and BPop). Each time step, the carrying capacity of each patch has a given probability of increasing or decreasing up to a maximum proportion.
…

MCA-SdA (ABM of mining-community-aquifer interactions in Salar de Atacama, Chile)
Wenjuan Liu | Published Tuesday, December 01, 2020 | Last modified Thursday, November 04, 2021This model represnts an unique human-aquifer interactions model for the Li-extraction in Salar de Atacama, Chile. It describes the local actors’ experience of mining-induced changes in the socio-ecological system, especially on groundwater changes and social stressors. Social interactions are designed specifically according to a long-term local fieldwork by Babidge et al. (2019, 2020). The groundwater system builds on the FlowLogo model by Castilla-Rho et al. (2015), which was then parameterized and calibrated with local hydrogeological inputs in Salar de Atacama, Chile. The social system of the ABM is defined and customozied based on empirical studies to reflect three major stressors: drought stress, population stress, and mining stress. The model reports evolution of groundwater changes and associated social stress dynamics within the modeled time frame.
COVID-19 US Masks
Dale Brearcliffe | Published Sunday, October 18, 2020This model is an abstract simulation of the COVID-19 virus in the United States population. It demonstrates how different masks of different types affect the progress of the virus.
Displaying 10 of 217 results population clear search