About the CoMSES Model Library more info
Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 866 results for "Jes%C3%BAs M Zamarre%C3%B1o" clear search
Peer reviewed Are Countertrade credits as flexible and efficient as cash? A novel approach to reducing income inequality using countertrade methodology.
Peter Malliaros | Published Monday, May 03, 2021 | Last modified Tuesday, May 11, 2021The impacts of income inequality can be seen everywhere, regardless of the country or the level of economic development. According to the literature review, income inequality has negative impacts in economic, social, and political variables. Notwithstanding of how well or not countries have done in reducing income inequality, none have been able to reduce it to a Gini Coefficient level of 0.2 or less.
This is the promise that a novel approach called Counterbalance Economics (CBE) provides without the need of increased taxes.
Based on the simulation, introducing the CBE into the Australian, UK, US, Swiss or German economies would result in an overall GDP increase of under 1% however, the level of inequality would be reduced from an average of 0.33 down to an average of 0.08. A detailed explanation of how to use the model, software, and data dependencies along with all other requirements have been included as part of the info tab in the model.
Confirmation Bias improves Performance in a Signal Detection Task and evolves in an Evolutionary Algorithm
Michael Vogrin | Published Monday, May 08, 2023Confirmation Bias is usually seen as a flaw of the human mind. However, in some tasks, it may also increase performance. Here, agents are confronted with a number of binary Signals (A, or B). They have a base detection rate, e.g. 50%, and after they detected one signal, they get biased towards this type of signal. This means, that they observe that kind of signal a bit better, and the other signal a bit worse. This is moderated by a variable called “bias_effect”, e.g. 10%. So an agent who detects A first, gets biased towards A and then improves its chance to detect A-signals by 10%. Thus, this agent detects A-Signals with the probability of 50%+10% = 60% and detects B-Signals with the probability of 50%-10% = 40%.
Given such a framework, agents that have the ability to be biased have better results in most of the scenarios.

Peer reviewed Strategy with Externalities
J M Applegate Glenn Hoetker | Published Thursday, December 21, 2017The SWE models firms search behaviour as the performance landscape shifts. The shift represents society’s pricing of negative externalities, and the performance landscape is an NK structure. The model is written in NetLogo.
Peer reviewed Empathy & Power
J M Applegate Ned Wellman | Published Monday, November 13, 2017 | Last modified Thursday, December 21, 2017The purpose of this model is to explore the effects of different power structures on a cross-functional team’s prosocial decision making. Are certain power distributions more conducive to the team making prosocial decisions?
The impact of scientific networks, affinity bias and scientific uncertainty on the public uptake of science
Sacha Ferrari | Published Thursday, January 23, 2025Ferrari, S., Lammers, W., Wenmackers, S. (forthcoming) How the structure of scientific communities could impact the public uptake of uncertain science. Philosophy of Science.
CA_Assiut_v1.0
Nina Schwarz Yang Chen m-m-abdelkader Mahmood Abdelkader | Published Sunday, October 09, 2022The purpose of the model is to simulate the future growth of human settlements in the Nile river valley in Egypt. The model contains processes to mimic spatial patterns found in the case study region.
Individual-based modelling as a tool for elephant poaching mitigation
Ernesto Carrella Richard Bailey Emily Neil Jens Koed Madsen Nicolas Payette | Published Tuesday, June 18, 2019 | Last modified Thursday, August 01, 2019We develop an IBM that predicts how interactions between elephants, poachers, and law enforcement affect poaching levels within a virtual protected area. The model is theoretical at this stage and is not meant to provide a realistic depiction of poaching, but instead to demonstrate how IBMs can expand upon the existing modelling work done in this field, and to provide a framework for future research. The model could be further developed into a useful management support tool to predict the outcomes of various poaching mitigation strategies at real-world locations. The model was implemented in NetLogo version 6.1.0.
We first compared a scenario in which poachers have prescribed, non-adaptive decision-making and move randomly across the landscape, to one in which poachers adaptively respond to their memories of elephant locations and where other poachers have been caught by law enforcement. We then compare a situation in which ranger effort is distributed unevenly across the protected area to one in which rangers patrol by adaptively following elephant matriarchal herds.
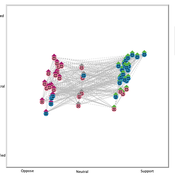
Gaming Polarisation: Using Agent-Based Simulations as A Dialogue Tool
Shaoni Wang | Published Friday, May 09, 2025This model aims to replicate the evolution of opinions and behaviours on a communal plan over time. It also aims to foster community dialogue on simulation outcomes, promoting inclusivity and engagement. Individuals (referred to as agents), grouped based on Sinus Milieus (Groh-Samberg et al., 2023), face a binary choice: support or oppose the plan. Motivated by experiential, social, and value needs (Antosz et al., 2019), their decision is influenced by how well the plan aligns with these fundamental needs.
A simple emulation-based computational model
Carlos M Fernández-Márquez Francisco J Vázquez | Published Tuesday, May 21, 2013 | Last modified Tuesday, February 05, 2019Emulation is one of the simplest and most common mechanisms of social interaction. In this paper we introduce a descriptive computational model that attempts to capture the underlying dynamics of social processes led by emulation.
Gradient Descent Simulation
Ilyes Azouani | Published Wednesday, March 18, 2026This model visualizes gradient descent optimization - the fundamental algorithm used to train neural networks and other machine learning models. Agents represent different optimization algorithms searching for the minimum of a loss landscape (the “error surface” that ML models try to minimize during training).
The model demonstrates how different optimizer types (SGD, Momentum with different parameters) behave on various loss landscapes, from simple bowls to the notoriously difficult Rosenbrock “banana valley” function. This helps build intuition about why certain optimization algorithms work better than others for different problem geometries.
HOW IT WORKS
…
Displaying 10 of 866 results for "Jes%C3%BAs M Zamarre%C3%B1o" clear search