Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 216 results Data clear search
Scientific disagreements and the diagnosticity of evidence
Matteo Michelini | Published Wednesday, December 13, 2023The present model is an abstract ABM designed for theoretical exploration and hypotheses generation. Its main aim is to explore the relationship between disagreement over the diagnostic value of evidence and the formation of polarization in scientific communities.
The model represents a scientific community in which scientists aim to determine whether hypothesis H is true, and we assume that agents are in a world in which H is indeed true. To this end, scientists perform experiments, interpret data and exchange their views on how diagnostic of H the obtained evidence is. Based on how the scientists conduct the inquiry, the community may reach a correct consensus (i.e. a situation in which every scientist agrees that H is correct) or not.

Peer reviewed Credit and debt market of low-income families
Márton Gosztonyi | Published Tuesday, December 12, 2023 | Last modified Friday, January 19, 2024The purpose of the Credit and debt market of low-income families model is to help the user examine how the financial market of low-income families works.
The model is calibrated based on real-time data which was collected in a small disadvantaged village in Hungary it contains 159 households’ social network and attributes data.
The simulation models the households’ money liquidity, expenses and revenue structures as well as the formal and informal loan institutions based on their network connections. The model forms an intertwined system integrated in the families’ local socioeconomic context through which families handle financial crises and overcome their livelihood challenges from one month to another.
The simulation-based on the abstract model of low-income families’ financial survival system at the bottom of the pyramid, which was described in following the papers:
…
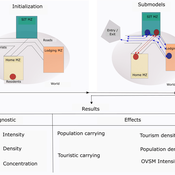
Peer reviewed ABM Overtourism Santa Marta
Janwar Moreno | Published Monday, October 23, 2023This model presents the simulation model of a city in the context of overtourism. The study area is the city of Santa Marta in Colombia. The purpose is to illustrate the spatial and temporal distribution of population and tourists in the city. The simulation analyzes emerging patterns that result from the interaction between critical components in the touristic urban system: residents, urban space, touristic sites, and tourists. The model is an Agent-Based Model (ABM) with the GAMA software. Also, it used public input data from statistical centers, geographical information systems, tourist websites, reports, and academic articles. The ABM includes assessing some measures used to address overtourism. This is a field of research with a low level of analysis for destinations with overtourism, but the ABM model allows it. The results indicate that the city has a high risk of overtourism, with spatial and temporal differences in the population distribution, and it illustrates the effects of two management measures of the phenomenon on different scales. Another interesting result is the proposed tourism intensity indicator (OVsm), taking into account that the tourism intensity indicators used by the literature on overtourism have an overestimation of tourism pressures.
Gender Disparity in COVID-19’s Impact on Academic Careers: An Agent-Based Model
S.R. Aurora (a.k.a. Mai P. Trinh) Chantal van Esch | Published Tuesday, September 26, 2023Prior to COVID-19, female academics accounted for 45% of assistant professors, 37% of associate professors, and 21% of full professors in business schools (Morgan et al., 2021). The pandemic arguably widened this gender gap, but little systemic data exists to quantify it. Our study set out to answer two questions: (1) How much will the COVID-19 pandemic have impacted the gender gap in U.S. business school tenured and tenure-track faculty? and (2) How much will institutional policies designed to help faculty members during the pandemic have affected this gender gap? We used agent-based modeling coupled with archival data to develop a simulation of the tenure process in business schools in the U.S. and tested how institutional interventions would affect this gender gap. Our simulations demonstrated that the gender gap in U.S. business schools was on track to close but would need further interventions to reach equality (50% females). In the long-term picture, COVID-19 had a small impact on the gender gap, as did dependent care assistance and tenure extensions (unless only women received tenure extensions). Changing performance evaluation methods to better value teaching and service activities and increasing the proportion of female new hires would help close the gender gap faster.
An Agent-Based Model of an Insurance Market driven by Supply and Demand with Imperfectly Estimated Strategies in C#
Rei England | Published Sunday, September 24, 2023This is a simulation of an insurance market where the premium moves according to the balance between supply and demand. In this model, insurers set their supply with the aim of maximising their expected utility gain while operating under imperfect information about both customer demand and underlying risk distributions.
There are seven types of insurer strategies. One type follows a rational strategy within the bounds of imperfect information. The other six types also seek to maximise their utility gain, but base their market expectations on a chartist strategy. Under this strategy, market premium is extrapolated from trends based on past insurance prices. This is subdivided according to whether the insurer is trend following or a contrarian (counter-trend), and further depending on whether the trend is estimated from short-term, medium-term, or long-term data.
Customers are modelled as a whole and allocated between insurers according to available supply. Customer demand is calculated according to a logit choice model based on the expected utility gain of purchasing insurance for an average customer versus the expected utility gain of non-purchase.
An Agent-Based Model of an Insurer's Estimated Capital Requirement in a Simple Insurance Market with Imperfect Information in C#
Rei England | Published Sunday, September 24, 2023This is an agent-based model of a simple insurance market with two types of agents: customers and insurers. Insurers set premium quotes for each customer according to an estimation of their underlying risk based on past claims data. Customers either renew existing contracts or else select the cheapest quote from a subset of insurers. Insurers then estimate their resulting capital requirement based on a 99.5% VaR of their aggregate loss distributions. These estimates demonstrate an under-estimation bias due to the winner’s curse effect.
A Data-Driven Approach of Layout Evaluation for Electric Vehicle Charging Infrastructure Using Agent-Based Simulation and GIS
yue zhang | Published Thursday, September 21, 2023The development and popularisation of new energy vehicles have become a global consensus. The shortage and unreasonable layout of electric vehicle charging infrastructure (EVCI) have severely restricted the development of electric vehicles. In the literature, many methods can be used to optimise the layout of charging stations (CSs) for producing good layout designs. However, more realistic evaluation and validation should be used to assess and validate these layout options. This study suggested an agent-based simulation (ABS) model to evaluate the layout designs of EVCI and simulate the driving and charging behaviours of electric taxis (ETs). In the case study of Shenzhen, China, GPS trajectory data were used to extract the temporal and spatial patterns of ETs, which were then used to calibrate and validate the actions of ETs in the simulation. The ABS model was developed in a GIS context of an urban road network with travelling speeds of 24 h to account for the effects of traffic conditions. After the high-resolution simulation, evaluation results of the performance of EVCI and the behaviours of ETs can be provided in detail and in summary. Sensitivity analysis demonstrates the accuracy of simulation implementation and aids in understanding the effect of model parameters on system performance. Maximising the time satisfaction of ET users and reducing the workload variance of EVCI were the two goals of a multiobjective layout optimisation technique based on the Pareto frontier. The location plans for the new CS based on Pareto analysis can significantly enhance both metrics through simulation evaluation.
Peer reviewed Co-adoption of low-carbon household energy technologies
Mart van der Kam Maria Lagomarsino Elie Azar Ulf Hahnel David Parra | Published Tuesday, August 29, 2023 | Last modified Friday, February 23, 2024The model simulates the diffusion of four low-carbon energy technologies among households: photovoltaic (PV) solar panels, electric vehicles (EVs), heat pumps, and home batteries. We model household decision making as the decision marking of one person, the agent. The agent decides whether to adopt these technologies. Hereby, the model can be used to study co-adoption behaviour, thereby going beyond traditional diffusion models that focus on the adop-tion of single technologies. The combination of these technologies is of particular interest be-cause (1) using the energy generated by PV solar panels for EVs and heat pumps can reduce emissions associated with transport and heating, respectively, and (2) EVs, heat pumps, and home batteries can help to integrate PV solar panels in local electricity grids by offering flexible demand (EVs and heat pumps) and energy storage (home batteries and EVs), thereby reducing grid impacts and associated upgrading costs.
The purpose of the model is to represent realistic adoption and co-adoption behaviour. This is achieved by grounding the decision model on the risks-as-feelings model (Loewenstein et al., 2001), theory from environmental and social psychology, and empirically informing agent be-haviour by survey-data among 1469 people in the Swiss region Romandie.
The model can be used to construct scenarios for the diffusion of the four low-carbon energy technologies depending on different contexts, and as a virtual experimentation environment for ex ante evaluation of policy interventions to stimulate adoption and co-adoption.
Pedestrian model
Gudrun Wallentin Dana Kaziyeva Martin Loidl Petra Stutz | Published Monday, August 07, 2023The model generates disaggregated traffic flows of pedestrians, simulating their daily mobility behaviour represented as probabilistic rules. Various parameters of physical infrastructure and travel behaviour can be altered and tested. This allows predicting potential shifts in traffic dynamics in a simulated setting. Moreover, assumptions in decision-making processes are general for mid-sized cities and can be applied to similar areas.
Together with the model files, there is the ODD protocol with the detailed description of model’s structure. Check the associated publication for results and evaluation of the model.
Installation
Download GAMA-platform (GAMA1.8.2 with JDK version) from https://gama-platform.github.io/. The platform requires a minimum of 4 GB of RAM.
…
Vaccine adoption with outgroup aversion using Cleveland area data
bruce1809 | Published Monday, July 31, 2023 | Last modified Sunday, August 06, 2023This model takes concepts from a JASSS paper this is accepted for the October, 2023 edition and applies the concepts to empirical data from counties surrounding and including Cleveland Ohio. The agent-based model has a proportional number of agents in each of the counties to represent the correct proportions of adults in these counties. The adoption decision probability uses the equations from Bass (1969) as adapted by Rand & Rust (2011). It also includes the Outgroup aversion factor from Smaldino, who initially had used a different imitation model on line grid. This model uses preferential attachment network as a metaphor for social networks influencing adoption. The preferential network can be adjusted in the model to be created based on both nodes preferred due to higher rank as well as a mild preference for nodes of a like group.
Displaying 10 of 216 results Data clear search