Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 123 results for "Manuel Scholz-Wäckerle" clear search
Aspiration, Attainment and Success: An agent-based model of distance-based school allocation
James Millington | Published Friday, November 02, 2012 | Last modified Friday, July 03, 2015The purpose of this model is to investigate mechanisms driving the geography of educational inequality and the consequences of these mechanisms for individuals with varying attributes and mobility.
An Agent-Based DSS for Word-of-Mouth Programs in Freemium Apps
Manuel Chica | Published Monday, September 05, 2016An agent-based framework that aggregates social network-level individual interactions to run targeting and rewarding programs for a freemium social app. Git source code in https://bitbucket.org/mchserrano/socialdynamicsfreemiumapps
HomininSpace
Fulco Scherjon | Published Friday, November 25, 2016 | Last modified Tuesday, October 06, 2020A modelling system to simulate Neanderthal demography and distribution in a reconstructed Western Europe for the late Middle Paleolithic.
ABM Household Decision Making on Solar Energy using Theory of Planned Behaviour
Tatiana Filatova Hannah Muelder | Published Tuesday, May 21, 2019The model aims at estimating household energy consumption and the related greenhouse gas (GHG) emissions reduction based on the behavior of the individual household under different operationalizations of the Theory of Planned Behaviour (TPB).
The original model is developed as a tool to explore households decisions regarding solar panel investments and cumulative consequences of these individual choices (i.e. diffusion of PVs, regional emissions savings, monetary savings). We extend the model to explore a methodological question regarding an interpretation of qualitative concepts from social science theories, specifically Theory of Planned Behaviour in a formal code of quantitative agent-based models (ABMs). We develop 3 versions of the model: one TPB-based ABM designed by the authors and two alternatives inspired by the TPB-ABM of Schwarz and Ernst (2009) and the TPB-ABM of Rai and Robinson (2015). The model is implemented in NetLogo.
MTC_Model_Pilditch&Madsen
Toby Pilditch | Published Friday, October 09, 2020Micro-targeted vs stochastic political campaigning agent-based model simulation. Written by Toby D. Pilditch (University of Oxford, University College London), in collaboration with Jens K. Madsen (University of Oxford, London School of Economics)
The purpose of the model is to explore the various impacts on voting intention among a population sample, when both stochastic (traditional) and Micto-targeted campaigns (MTCs) are in play. There are several stages of the model: initialization (setup), campaigning (active running protocols) and vote-casting (end of simulation). The campaigning stage consists of update cycles in which “voters” are targeted and “persuaded” - updating their beliefs in the campaign candidate / policies.
Network Behaviour Diffusion
Jennifer Badham | Published Saturday, October 02, 2021This model implements two types of network diffusion from an initial group of activated nodes. In complex contagion, a node is activated if the proportion of neighbour nodes that are already activated exceeds a given threshold. This is intended to represented the spread of health behaviours. In simple contagion, an activated node has a given probability of activating its inactive neighbours and re-tests each time step until all of the neighbours are activated. This is intended to represent information spread.
A range of networks are included with the model from secondary school friendship networks. The proportion of nodes initially activated and the method of selecting those nodes are controlled by the user.

Modeling financial networks based on interpersonal trust
Michael Roos Anna Klabunde | Published Wednesday, May 29, 2013 | Last modified Thursday, November 28, 2013We build a stylized model of a network of business angel investors and start-up entrepreneurs. Decisions are based on trust as a decision making tool under true uncertainty.
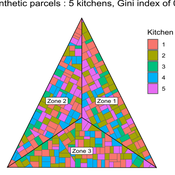
MeReDiem : Fallow Land Simulations to examine the conditions of sustainable village livelihood
Etienne DELAY Paul Chapron Mathieu | Published Monday, January 20, 2025 | Last modified Tuesday, January 21, 2025The MeReDiem model aims to simulate the effect of socio-agricultural practices of farmers and pastors on the food sustainability and soil fertility of a serrer village, in Senegal. The model is a central part of a companion modeling and exploration approach, described in a paper, currently under review)
The village population is composed of families (kitchens). Kitchens cultivate their land parcels to feed their members, aiming for food security at the family level. On a global level , the village tries to preserve the community fallow land as long as possible.
Kitchens sizes vary depending on the kitchens food production, births and migration when food is insufficient.
…
PolicySpace: agent-based modeling
Francisco Miguel Quesada Bernardo Furtado Isaque Daniel Rocha Eberhardt | Published Tuesday, March 06, 2018PolicySpace models public policies within an empirical, spatial environment using data from 46 metropolitan regions in Brazil. The model contains citizens, markets, residences, municipalities, commuting and a the tax scheme. In the associated publications (book in press and https://arxiv.org/abs/1801.00259) we validate the model and demonstrate an application of the fiscal analysis. Besides providing the basics of the platform, our results indicate the relevance of the rules of taxes transfer for cities’ quality of life.
Relative Agreement Model and Network Structure
Spiro Maroulis David Adelberg | Published Friday, January 29, 2016This adaptation of the Relative Agreement model of opinion dynamics (Deffuant et al. 2002) extends the Meadows and Cliff (2012) implementation of this model in a manner that explores the effect of the network structure among the agents.
Displaying 10 of 123 results for "Manuel Scholz-Wäckerle" clear search