Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 197 results decision clear search
An agent-based model of the journey of victim/survivors through local authority domestic abuse support services in the UK
Bruce Edmonds | Published Monday, July 28, 2025This model played a small part in the UK government’s review of the working of local authority implementation of the Domestic Abuse legislation. The model explicitly represents victim-survivor families as they: (a) try to contact the local DA support system, (b) are triaged by the system and (if there is space) allocated to safe temporary accomodation (c) recieve support services from this position and (d) eventually move on to more permenant accomodation. The purpose of the model was to understand some possible ways in which the implementation of DA Duty, might be frustrated in practice, the identification of gaps in the evidence base and to inform the developing Theory of Change. The key measures used for assessing outcomes in the model were the number of families helped and the services that were delivered to them. The exploration was grounded for in two archetypal cases: that of a relatively immature system for the delivery of DA services and a more mature one (based on actual local authority cases, but not based on any single one). See the official report under associated publications for a summary of results.

BESTMAP-ABM-DE is an agent-based model to determine the adoption and spatial allocation of selected agri-environmental schemes (AES) by individual farmers in the Mulde River Basin located in Western Saxony, Germany. The selected AES are buffer areas, cover crops, maintaining permanent grassland and conversion of arable land to permanent grassland. While the first three schemes have already been offered in the case study area, the latter scheme is a hypothetical scheme designed to test the impact of potential policy changes. For the first model analyses, only the currently offered schemes are considered. With the model, the effect of different scenarios of policy design on patterns of adoption can be investigated. In particular, the model can be used to study the social-ecological consequences of agricultural policies at different spatial and temporal scales and, in combination with biophysical models, test the ecological implications of different designs of the EU’s Common Agricultural Policy. The model was developed in the BESTMAP project.

Peer reviewed soslivestock model
Marco Janssen Irene Perez Ibarra Diego J. Soler-Navarro Alicia Tenza Peral | Published Wednesday, May 28, 2025 | Last modified Tuesday, June 10, 2025The purpose of this model is to analyze how different management strategies affect the wellbeing, sustainability and resilience of an extensive livestock system under scenarios of climate change and landscape configurations. For this purpose, it simulates one cattle farming system, in which agents (cattle) move through the space using resources (grass). Three farmer profiles are considered: 1) a subsistence farmer that emphasizes self-sufficiency and low costs with limited attention to herd management practices, 2) a commercial farmer focused on profit maximization through efficient production methods, and 3) an environmental farmer that prioritizes conservation of natural resources and animal welfare over profit maximization. These three farmer profiles share the same management strategies to adapt to climate and resource conditions, but differ in their goals and decision-making criteria for when, how, and whether to implement those strategies. This model is based on the SequiaBasalto model (Dieguez Cameroni et al. 2012, 2014, Bommel et al. 2014 and Morales et al. 2015), replicated in NetLogo by Soler-Navarro et al. (2023).
One year is 368 days. Seasons change every 92 days. Each step begins with the growth of grass as a function of climate and season. This is followed by updating the live weight of animals according to the grass height of their patch, and grass consumption, which is determined based on the updated live weight. Animals can be supplemented by the farmer in case of severe drought. After consumption, cows grow and reproduce, and a new grass height is calculated. This updated grass height value becomes the starting grass height for the next day. Cows then move to the next area with the highest grass height. After that, cattle prices are updated and cattle sales are held on the first day of fall. In the event of a severe drought, special sales are held. Finally, at the end of the day, the farm balance and the farmer’s effort are calculated.
Peer reviewed Urban Transport Mode Choices
Kathleen Salazar -Serna Lorena Cadavid Carlos Franco | Published Thursday, May 22, 2025The model represents urban commuters’ transport mode choices among cars, public transit, and motorcycles—a mode highly prevalent in developing countries. Using an agent-based modeling approach, it simulates transport dynamics and serves as a testbed for evaluating policies aimed at improving mobility.
The model simulates an ecosystem of human agents who decide, at each time step, which mode of transportation to use for commuting to work. Their decision is based on a combination of personal satisfaction with their most recent journey—evaluated across a vector of individual needs—the information they crowdsource from their social network, and their personal uncertainty regarding trying new transport options.
Agents are assigned demographic attributes such as sex, age, and income level, and are distributed across city neighborhoods according to their socioeconomic status. To represent social influence in decision-making, agents are connected via a scale-free social network topology, where connections are more likely among agents within the same socioeconomic group, reflecting the tendency of individuals to form social ties with similar others.
…
Gaming Polarisation: Using Agent-Based Simulations as A Dialogue Tool
Shaoni Wang | Published Friday, May 09, 2025This model aims to replicate the evolution of opinions and behaviours on a communal plan over time. It also aims to foster community dialogue on simulation outcomes, promoting inclusivity and engagement. Individuals (referred to as agents), grouped based on Sinus Milieus (Groh-Samberg et al., 2023), face a binary choice: support or oppose the plan. Motivated by experiential, social, and value needs (Antosz et al., 2019), their decision is influenced by how well the plan aligns with these fundamental needs.
Agent-Based Model for Multiple Team Membership (ABMMTM)
Andrew Collins | Published Thursday, April 03, 2025The Agent-Based Model for Multiple Team Membership (ABMMTM) simulates design teams searching for viable design solutions, for a large design project that requires multiple design teams that are working simultaneously, under different organizational structures; specifically, the impact of multiple team membership (MTM). The key mechanism under study is how individual agent-level decision-making impacts macro-level project performance, specifically, wage cost. Each agent follows a stochastic learning approach, akin to simulated annealing or reinforcement learning, where they iteratively explore potential design solutions. The agent evaluates new solutions based on a random-walk exploration, accepting improvements while rejecting inferior designs. This iterative process simulates real-world problem-solving dynamics where designers refine solutions based on feedback.
As a proof-of-concept demonstration of assessing the macro-level effects of MTM in organizational design, we developed this agent-based simulation model which was used in a simulation experiment. The scenario is a system design project involving multiple interdependent teams of engineering designers. In this scenario, the required system design is split into three separate but interdependent systems, e.g., the design of a satellite could (trivially) be split into three components: power source, control system, and communication systems; each of three design team is in charge of a design of one of these components. A design team is responsible for ensuring its proposed component’s design meets the design requirement; they are not responsible for the design requirements of the other components. If the design of a given component does not affect the design requirements of the other components, we call this the uncoupled scenario; otherwise, it is a coupled scenario.
Multi-Agent Socio-Ecological Hani Terrace Model
Lei Dong Yunnan University | Published Saturday, March 29, 2025This model is to explore the changes of paddy field landscape and household livelihood structure in the village under different policy scenarios, evaluate the eco-social effects of different policies, and provide decision support tools for proposing effective and feasible policies.

A simple computational algorithm for simulating population substance use
Jacob Borodovsky | Published Thursday, March 27, 2025This code simulates individual-level, longitudinal substance use patterns that can be used to understand how cross-sectional U-shaped distributions of population substance use emerge. Each independent computational object transitions between two states: using a substance (State 1), or not using a substance (State 2). The simulation has two core components. Component 1: each object is assigned a unique risk factor transition probability and unique protective factor transition probability. Component 2: each object’s current decision to use or not use the substance is influenced by the object’s history of decisions (i.e., “path dependence”).
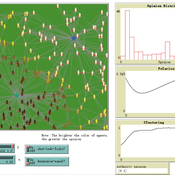
How Does Culture Affect Vaccination Opinion Polarisation?
Teng Li | Published Monday, March 10, 2025This model is to explore how individuals’ cultural backgrounds may play a role in their Covid vaccination decision-making. Two cultural dimensions of collectivism/individualism and power distance are considered. Through the experimental scenarios, we find that Covid-vaccination opinions in collectivist societies can also be considerably polarised, if the power distance is less and authorities less centralised. This result complements the popular idea that cultural collectivism is usually associated with a high degree of social consensus. Hopefully, this study will help explain countries’ difference in the response of Covid vaccination programs.
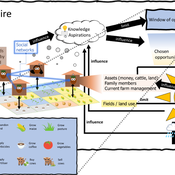
3spire: an agent-based model for exploring aspiration adaptation theory and its implications on smallholder farmers in Ethiopia
ateeuw Yue Dou Markus A Meyer Andrew Nelson | Published Sunday, February 16, 20253spire is an ABM where farming households make management decisions aimed at satisficing along the aspirational dimensions: food self-sufficiency, income, and leisure. Households decision outcomes depend on their social networks, knowledge, assets, household needs, past management, and climate/market trends
Displaying 10 of 197 results decision clear search