Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 330 results for "J Hall" clear search
Tail biting behaviour in pigs
Iris J.M.M. Boumans Iris Jmm Boumans | Published Friday, April 22, 2016 | Last modified Wednesday, September 14, 2016The model simulates tail biting behaviour in pigs and how they can turn into a biter and/or victim. The effect of a redirected motivation, behavioural changes in victims and preference to bite a lying pig on tail biting can be tested in the model
A simple emulation-based computational model
Carlos M Fernández-Márquez Francisco J Vázquez | Published Tuesday, May 21, 2013 | Last modified Tuesday, February 05, 2019Emulation is one of the simplest and most common mechanisms of social interaction. In this paper we introduce a descriptive computational model that attempts to capture the underlying dynamics of social processes led by emulation.
Heterogeneity of preferences and the dynamics of voluntary contributions to public goods
Engi Amin Amal Soliman Mohamed Abouelela | Published Thursday, August 18, 2016 | Last modified Thursday, January 25, 2018This model simulates the heterogeneity of preferences in a PG game and how the interaction between them affects the dynamics of voluntary contributions. Model is based on the results of a human-based experiment.
DiDIY Factory
Ruth Meyer | Published Tuesday, February 20, 2018The DiDIY-Factory model is a model of an abstract factory. Its purpose is to investigate the impact Digital Do-It-Yourself (DiDIY) could have on the domain of work and organisation.
DiDIY can be defined as the set of all manufacturing activities (and mindsets) that are made possible by digital technologies. The availability and ease of use of digital technologies together with easily accessible shared knowledge may allow anyone to carry out activities that were previously only performed by experts and professionals. In the context of work and organisations, the DiDIY effect shakes organisational roles by such disintermediation of experts. It allows workers to overcome the traditionally strict organisational hierarchies by having direct access to relevant information, e.g. the status of machines via real-time information systems implemented in the factory.
A simulation model of this general scenario needs to represent a more or less abstract manufacturing firm with supervisors, workers, machines and tasks to be performed. Experiments with such a model can then be run to investigate the organisational structure –- changing from a strict hierarchy to a self-organised, seemingly anarchic organisation.
Roman Amphora reuse
Tom Brughmans | Published Wednesday, August 07, 2019 | Last modified Wednesday, March 15, 2023UPDATE in V1.1.0: missing input data files added; relative paths to input data files changed to “../data/FILENAME”
A model that allows for representing key theories of Roman amphora reuse, to explore the differences in the distribution of amphorae, re-used amphorae and their contents.
This model generates simulated distributions of prime-use amphorae, primeuse contents (e.g. olive oil) and reused amphorae. These simulated distributions will differ between experiments depending on the experiment’s variable settings representing the tested theory: variations in the probability of reuse, the supply volume, the probability of reuse at ports. What we are interested in teasing out is what the effect is of each theory on the simulated amphora distributions.
…
LogoClim: WorldClim in NetLogo
Daniel Vartanian Leandro Garcia Aline Martins de Carvalho Aline | Published Thursday, July 03, 2025 | Last modified Tuesday, September 16, 2025LogoClim is a NetLogo model for simulating and visualizing global climate conditions. It allows researchers to integrate high-resolution climate data into agent-based models, supporting reproducible research in ecology, agriculture, environmental sciences, and other fields that rely on climate data.
The model utilizes raster data to represent climate variables such as temperature and precipitation over time. It incorporates historical data (1951-2024) and future climate projections (2021-2100) derived from global climate models under various Shared Socioeconomic Pathways (SSPs, O’Neill et al., 2017). All climate inputs come from WorldClim 2.1, a widely used source of high-resolution, interpolated climate datasets based on weather station observations worldwide (Fick & Hijmans, 2017).
LogoClim follows the FAIR Principles for Research Software (Barker et al., 2022) and is openly available on the CoMSES Network and GitHub. See the Logônia model for an example of its integration into a full NetLogo simulation.
Can ethnic tolerance curb self-reinforcing school segregation? A theoretical Agent Based Model
Lucas Sage Andreas Flache | Published Monday, August 10, 2020Schelling and Sakoda prominently proposed computational models suggesting that strong ethnic residential segregation can be the unintended outcome of a self-reinforcing dynamic driven by choices of individuals with rather tolerant ethnic preferences. There are only few attempts to apply this view to school choice, another important arena in which ethnic segregation occurs. In the current paper, we explore with an agent-based theoretical model similar to those proposed for residential segregation, how ethnic tolerance among parents can affect the level of school segregation. More specifically, we ask whether and under which conditions school segregation could be reduced if more parents hold tolerant ethnic preferences. We move beyond earlier models of school segregation in three ways. First, we model individual school choices using a random utility discrete choice approach. Second, we vary the pattern of ethnic segregation in the residential context of school choices systematically, comparing residential maps in which segregation is unrelated to parents’ level of tolerance to residential maps reflecting their ethnic preferences. Third, we introduce heterogeneity in tolerance levels among parents belonging to the same group. Our simulation experiments suggest that ethnic school segregation can be a very robust phenomenon, occurring even when about half of the population prefers mixed to segregated schools. However, we also identify a “sweet spot” in the parameter space in which a larger proportion of tolerant parents makes the biggest difference. This is the case when parents have moderate preferences for nearby schools and there is only little residential segregation. Further experiments are presented that unravel the underlying mechanisms.
Friendship Games Rev 1.0
David Dixon | Published Friday, October 07, 2011 | Last modified Saturday, April 27, 2013A friendship game is a kind of network game: a game theory model on a network. This is a NetLogo model of an agent-based adaptation of “‘Friendship-based’ Games” by PJ Lamberson. The agents reach an equilibrium that depends on the strategy played and the topology of the network.
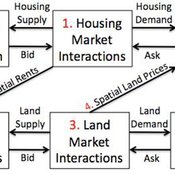
Coupled Housing and Land Markets (CHALMS)
Nicholas Magliocca Virginia Mcconnell Margaret Walls | Published Friday, November 02, 2012 | Last modified Monday, October 27, 2014CHALMS simulates housing and land market interactions between housing consumers, developers, and farmers in a growing ex-urban area.
A data-informed bounded-confidence opinion dynamics model
Bruce Edmonds | Published Wednesday, March 10, 2021The simulation is a variant of the “ToRealSim OD variants - base v2.7” base model, which is based on the standard DW opinion dynamics model (but with the differences that rather than one agent per tick randomly influencing another, all agents randomly influence one other per tick - this seems to make no difference to the outcomes other than to scale simulation time). Influence can be made one-way by turning off the two-way? switch
Various additional variations and sources of noise are possible to test robustness of outcomes to these (compared to DW model).
In this version agent opinions change following the empirical data collected in some experiments (Takács et al 2016).
Such an algorithm leaves no role for the uncertainties in other OD models. [Indeed the data from (Takács et al 2016) indicates that there can be influence even when opinion differences are large - which violates a core assumption of these]. However to allow better comparison with other such models there is a with-un? switch which allows uncertainties to come into play. If this is on, then influence (according to above algorithm) is only calculated if the opinion difference is less than the uncertainty. If an agent is influenced uncertainties are modified in the same way as standard DW models.
Displaying 10 of 330 results for "J Hall" clear search