About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 3 of 3 results task performance clear search
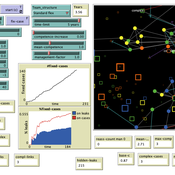
Team Structure and Task Performance
Davide Secchi Martin Neumann | Published Monday, August 05, 2024This model was designed to study resilience in organizations. Inspired by ethnographic work, it follows the simple goal to understand whether team structure affects the way in which tasks are performed. In so doing, it compares the ‘hybrid’ data-inspired structure with three more traditional structures (i.e. hierarchy, flexible/relaxed hierarchy, and anarchy/disorganization).

The uFUNK Model
Davide Secchi | Published Monday, August 31, 2020The agent-based simulation is set to work on information that is either (a) functional, (b) pseudo-functional, (c) dysfunctional, or (d) irrelevant. The idea is that a judgment on whether information falls into one of the four categories is based on the agent and its network. In other words, it is the agents who interprets a particular information as being (a), (b), (c), or (d). It is a decision based on an exchange with co-workers. This makes the judgment a socially-grounded cognitive exercise. The uFUNK 1.0.2 Model is set on an organization where agent-employee work on agent-tasks.

Team Problem Solving and Motivation under Disorganization
Dinuka Herath | Published Sunday, August 13, 2017The model combines the two elements of disorganization and motivation to explore their impact on teams. Effects of disorganization on team task performance (problem solving)