Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 79 results society clear search

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
Peer reviewed ABM for Social Cohesion and Wellbeing(ABMSCWB)
Taseer Salahuddin Hasan Vergil | Published Wednesday, June 25, 2025ABM model studying impact of social cohesion on wellbeing of a society. Ibn Khaldun’s cyclical theory of history is being used as the theoretical lens along with some other theories. Social cohesion is measured as TSC = (TVE + 2 * (TPI * TPL - TNI * TNL))/((TPI+TNI))
Where
TSC total-social-cohesion ; Variable for social cohesion
TPI total-positive-interactions ; Count of positive interactions
TNI total-negative-interactions ; Count of negative interactions
TPL total-positive-learning ; Count of positive learning outcomes
…
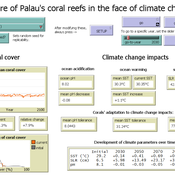
Development of coral reefs under climate change impacts and adaptation options
Nina Preußler | Published Friday, May 30, 2025This NetLogo model simulates how coral reefs around the islands of Palau would develop under different emission scenarios and with selected adaptation strategies. Reef health is indicated by coral cover (%) and is affected by four major climate change impacts: increasing sea surface temperature, sea level rise, ocean acidification, and more intense typhoons. The model differentiates between inner and outer reefs, with the former naturally adapted to warmer, more acidic waters. The simulation includes bleaching events and possible recovery. In addition, the user can choose between different coral transplantation strategies as well as regulate natural thermal adaptation rates.

Peer reviewed Descriptive Norm and Fraud Dynamics
Alexandra Eckert Matthias Meyer Christian Stindt | Published Tuesday, January 07, 2025 | Last modified Tuesday, March 24, 2026The “Descriptive Norm and Fraud Dynamics” model demonstrates how fraudulent behavior can either proliferate or be contained within non-hierarchical organizations, such as peer networks, through social influence taking the form of a descriptive norm. This model expands on the fraud triangle theory, which posits that an individual must concurrently possess a financial motive, perceive an opportunity, and hold a pro-fraud attitude to engage in fraudulent activities (red agent). In the absence of any of these elements, the individual will act honestly (green agent).
The model explores variations in a descriptive norm mechanism, ranging from local distorted knowledge to global perfect knowledge. In the case of local distorted knowledge, agents primarily rely on information from their first-degree colleagues. This knowledge is often distorted because agents are slow to update their empirical expectations, which are only partially revised after one-to-one interactions. On the other end of the spectrum, local perfect knowledge is achieved by incorporating a secondary source of information into the agents’ decision-making process. Here, accurate information provided by an observer is used to update empirical expectations.
The model shows that the same variation of the descriptive norm mechanism could lead to varying aggregate fraud levels across different fraud categories. Two empirically measured norm sensitivity distributions associated with different fraud categories can be selected into the model to see the different aggregate outcomes.
Peer reviewed AgModel
Isaac Ullah | Published Friday, December 06, 2024AgModel is an agent-based model of the forager-farmer transition. The model consists of a single software agent that, conceptually, can be thought of as a single hunter-gather community (i.e., a co-residential group that shares in subsistence activities and decision making). The agent has several characteristics, including a population of human foragers, intrinsic birth and death rates, an annual total energy need, and an available amount of foraging labor. The model assumes a central-place foraging strategy in a fixed territory for a two-resource economy: cereal grains and prey animals. The territory has a fixed number of patches, and a starting number of prey. While the model is not spatially explicit, it does assume some spatiality of resources by including search times.
Demographic and environmental components of the simulation occur and are updated at an annual temporal resolution, but foraging decisions are “event” based so that many such decisions will be made in each year. Thus, each new year, the foraging agent must undertake a series of optimal foraging decisions based on its current knowledge of the availability of cereals and prey animals. Other resources are not accounted for in the model directly, but can be assumed for by adjusting the total number of required annual energy intake that the foraging agent uses to calculate its cereal and prey animal foraging decisions. The agent proceeds to balance the net benefits of the chance of finding, processing, and consuming a prey animal, versus that of finding a cereal patch, and processing and consuming that cereal. These decisions continue until the annual kcal target is reached (balanced on the current human population). If the agent consumes all available resources in a given year, it may “starve”. Starvation will affect birth and death rates, as will foraging success, and so the population will increase or decrease according to a probabilistic function (perturbed by some stochasticity) and the agent’s foraging success or failure. The agent is also constrained by labor caps, set by the modeler at model initialization. If the agent expends its yearly budget of person-hours for hunting or foraging, then the agent can no longer do those activities that year, and it may starve.
Foragers choose to either expend their annual labor budget either hunting prey animals or harvesting cereal patches. If the agent chooses to harvest prey animals, they will expend energy searching for and processing prey animals. prey animals search times are density dependent, and the number of prey animals per encounter and handling times can be altered in the model parameterization (e.g. to increase the payoff per encounter). Prey animal populations are also subject to intrinsic birth and death rates with the addition of additional deaths caused by human predation. A small amount of prey animals may “migrate” into the territory each year. This prevents prey animals populations from complete decimation, but also may be used to model increased distances of logistic mobility (or, perhaps, even residential mobility within a larger territory).
…
The Urban Drought Nexus Tool
Roger Cremades Muhamad Khairulbahri | Published Thursday, December 14, 2023The “Urban Drought Nexus Tool” is a system dynamics model, aiming to facilitate the co-development of climate services for cities under increasing droughts. The tool integrates multiple types of information and still can be applied to other case studies with minimal adjustments on the parameters of land use, water consumption and energy use in the water sector. The tool needs hydrological projections under climate scenarios to evaluate climatic futures, and requires the co-creation of socio-economic future scenarios with local stakeholders. Thus it is possible to provide specific information about droughts taking into account future water availability and future water consumption. Ultimately, such complex system as formed by the water-energy-land nexus can be reduced to single variables of interest, e.g. the number of events with no water available in the future and their length, so that the complexities are reduced and the results can be conveyed to society in an understandable way, including the communication of uncertainties. The tool and an explanatory guide in pdf format are included. Planned further developments include calibrating the system dynamics model with the social dynamics behind each flow with agent-based models.
Hollywood Underrepresentation Simulated Causes
Carmen Iasiello | Published Sunday, November 26, 2023Presented here is a socioeconomic agent-based model (ABM) to examine the Hollywood labor system as a network within a simulated movie labor market based on preferential attachment and compare the findings with 50 co-production ego networks during the 2015 movie year. Using the ABM, I test the role slight individual preference for racial and ethnic similarity within one’s own network at the microlevel and find that it is insufficient to explain the phenomena of racial and ethnic underrepresentation at the macrolevel. The ABM also includes the ability to test alternative explanations, such as overt opportunity loss as a possible explanation.
ABM Simulation of Transition from Late Longshan Cultures to Early Erlitou Culture
Carmen Iasiello | Published Sunday, November 26, 2023Within the archeological record for Bronze Age Chinese culture, there continues to be a gap in our understanding of the sudden rise of the Erlitou State from the previous late Longshan chiefdoms. In order to examine this period, I developed and used an agent-based model (ABM) to explore possible socio-politically relevant hypotheses for the gap between the demise of the late Longshan cultures and rise of the first state level society in East Asia. I tested land use strategy making and collective action in response to drought and flooding scenarios, the two plausible environmental hazards at that time. The model results show cases of emergent behavior where an increase in social complexity could have been experienced if a catastrophic event occurred while the population was sufficiently prepared for a different catastrophe, suggesting a plausible lead for future research into determining the life of the time period.
The ABM published here was originally developed in 2016 and its results published in the Proceedings of the 2017 Winter Simulation Conference.

Peer reviewed COMMONSIM: Simulating the utopia of COMMONISM
Lena Gerdes Manuel Scholz-Wäckerle Ernest Aigner Stefan Meretz Jens Schröter Hanno Pahl Annette Schlemm Simon Sutterlütti | Published Sunday, November 05, 2023This research article presents an agent-based simulation hereinafter called COMMONSIM. It builds on COMMONISM, i.e. a large-scale commons-based vision for a utopian society. In this society, production and distribution of means are not coordinated via markets, exchange, and money, or a central polity, but via bottom-up signalling and polycentric networks, i.e. ex-ante coordination via needs. Heterogeneous agents care for each other in life groups and produce in different groups care, environmental as well as intermediate and final means to satisfy sensual-vital needs. Productive needs decide on the magnitude of activity in groups for a common interest, e.g. the production of means in a multi-sectoral artificial economy. Agents share cultural traits identified by different behaviour: a propensity for egoism, leisure, environmentalism, and productivity. The narrative of this utopian society follows principles of critical psychology and sociology, complexity and evolution, the theory of commons, and critical political economy. The article presents the utopia and an agent-based study of it, with emphasis on culture-dependent allocation mechanisms and their social and economic implications for agents and groups.
An Opinion Dynamics of Science? Agent-Based Modeling of Knowledge Spread
Bernardo Buarque | Published Thursday, April 13, 2023We present a socio-epistemic model of science inspired by the existing literature on opinion dynamics. In this model, we embed the agents (or scientists) into social networks - e.g., we link those who work in the same institutions. And we place them into a regular lattice - each representing a unique mental model. Thus, the global environment describes networks of concepts connected based on their similarity. For instance, we may interpret the neighbor lattices as two equivalent models, except one does not include a causal path between two variables.
Agents interact with one another and move across the epistemic lattices. In other words, we allow the agents to explore or travel across the mental models. However, we constrain their movements based on absorptive capacity and cognitive coherence. Namely, in each round, an agent picks a focal point - e.g., one of their colleagues - and will move towards it. But the agents’ ability to move and speed depends on how far apart they are from the focal point - and if their new position is cognitive/logic consistent.
Therefore, we propose an analytical model that examines the connection between agents’ accumulated knowledge, social learning, and the span of attitudes towards mental models in an artificial society. While we rely on the example from the General Theory of Relativity renaissance, our goal is to observe what determines the creation and diffusion of mental models. We offer quantitative and inductive research, which collects data from an artificial environment to elaborate generalized theories about the evolution of science.
Displaying 10 of 79 results society clear search