Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 151 results C clear search
Narragansett Bay (RI) Recreational Fishery ABM
Tyler Pavlowich Anne Innes-Gold Margaret Heinichen M. Conor McManus Jason McNamee Jeremy Collie Austin Humphries | Published Monday, June 21, 2021This model is based on the Narragansett Bay, RI recreational fishery. The two types of agents are piscivorous fish and fishers (shore and boat fishers are separate “breeds”). Each time step represents one week. Open season is weeks 1-26, assuming fishing occurs during half the year. At each weekly time step, fish agents grow, reproduce, and die. Fisher agents decide whether or not to fish based on their current satisfaction level, and those that do go fishing attempt to catch a fish. If they are successful, they decide whether to keep or release the fish. In our publication, this model was linked to an Ecopath with Ecosim food web model where the commercial harvest of forage fish affected the biomass of piscivorous fish - which then became the starting number of piscivorous fish for this ABM. The number of fish caught in a season of this ABM was converted to a fishing pressure and input back into the food web model.
Open Peer Review Model
Federico Bianchi | Published Monday, May 24, 2021This is an agent-based model of a population of scientists alternatively authoring or reviewing manuscripts submitted to a scholarly journal for peer review. Peer-review evaluation can be either ‘confidential’, i.e. the identity of authors and reviewers is not disclosed, or ‘open’, i.e. authors’ identity is disclosed to reviewers. The quality of the submitted manuscripts vary according to their authors’ resources, which vary according to the number of publications. Reviewers can assess the assigned manuscript’s quality either reliably of unreliably according to varying behavioural assumptions, i.e. direct/indirect reciprocation of past outcome as authors, or deference towards higher-status authors.
Knowledge Based Economy
Guido Fioretti Sirio Capizzi Ruggero Rossi Martina Casari Ala Jlif | Published Tuesday, May 18, 2021Knowledge Based Economy (KBE) is an artificial economy where firms placed in geographical space develop original knowledge, imitate one another and eventually recombine pieces of knowledge. In KBE, consumer value arises from the capability of certain pieces of knowledge to bridge between existing items (e.g., Steve Jobs illustrated the first smartphone explaining that you could make a call with it, but also listen to music and navigate the Internet). Since KBE includes a mechanism for the generation of value, it works without utility functions and does not need to model market exchanges.

Peer reviewed Social Consequences of Past Compound Events - Laacher See Eruption
Kevin Su Brennen Bouwmeester | Published Monday, May 17, 2021Resilience of humans in the Upper Paleolithic could provide insights in how to defend against today’s environmental threats. Approximately 13,000 years ago, the Laacher See volcano located in present-day western Germany erupted cataclysmically. Archaeological evidence suggests that this is eruption – potentially against the background of a prolonged cold spell – led to considerable culture change, especially at some distance from the eruption (Riede, 2017). Spatially differentiated and ecologically mediated effects on contemporary social networks as well as social transmission effects mediated by demographic changes in the eruption’s wake have been proposed as factors that together may have led to, in particular, the loss of complex technologies such as the bow-and-arrow (Riede, 2014; Riede, 2009).
This model looks at the impact of the interaction between climate change trajectory and an extreme event, such as the Laacher See eruption, on the generational development of hunter-gatherer bands. Historic data is used to model the distribution and population dynamics of hunter-gatherer bands during these circumstances.
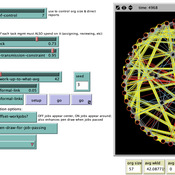
Formal Organization Hierarchy and Informal Networks - "The Company Behind the Org Chart"
Tom Briggs | Published Sunday, April 18, 2021A generalized organizational agent- based model (ABM) containing both formal organizational hierarchy and informal social networks simulates organizational processes that occur over both formal network ties and informal networks.
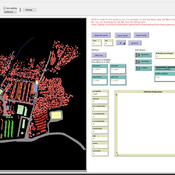
AIforGoodSimulator - Modeling Covid-19 Spread and Potential Interventions in Refugee Camps
Shyaam Ramkumar Woi Sok Oh | Published Thursday, March 18, 2021The Netlogo model is a conceptualization of the Moria refugee camp, capturing the household demographics of refugees in the camp, a theoretical friendship network based on values, and an abstraction of their daily activities. The model then simulates how Covid-19 could spread through the camp if one refugee is exposed to the virus, utilizing transmission probabilities and the stages of disease progression of Covid-19 from susceptible to exposed to asymptomatic / symptomatic to mild / severe to recovered from literature. The model also incorporates various interventions - PPE, lockdown, isolation of symptomatic refugees - to analyze how they could mitigate the spread of the virus through the camp.
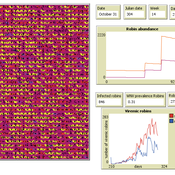
Peer reviewed AMRO_CULEX_WNV
Aniruddha Belsare Jennifer Owen | Published Saturday, February 27, 2021 | Last modified Thursday, March 11, 2021An agent-based model simulating West Nile Virus dynamics in a one host (American robin)-one vector (Culex spp. mosquito) system. ODD improved and code cleaned.
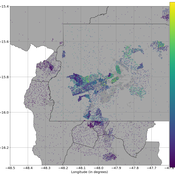
Peer reviewed PolicySpace2: modeling markets and endogenous public policies
Bernardo Furtado | Published Thursday, February 25, 2021 | Last modified Friday, January 14, 2022Policymakers decide on alternative policies facing restricted budgets and uncertain future. Designing public policies is further difficult due to the need to decide on priorities and handle effects across policies. Housing policies, specifically, involve heterogeneous characteristics of properties themselves and the intricacy of housing markets and the spatial context of cities. We propose PolicySpace2 (PS2) as an adapted and extended version of the open source PolicySpace agent-based model. PS2 is a computer simulation that relies on empirically detailed spatial data to model real estate, along with labor, credit, and goods and services markets. Interaction among workers, firms, a bank, households and municipalities follow the literature benchmarks to integrate economic, spatial and transport scholarship. PS2 is applied to a comparison among three competing public policies aimed at reducing inequality and alleviating poverty: (a) house acquisition by the government and distribution to lower income households, (b) rental vouchers, and (c) monetary aid. Within the model context, the monetary aid, that is, smaller amounts of help for a larger number of households, makes the economy perform better in terms of production, consumption, reduction of inequality, and maintenance of financial duties. PS2 as such is also a framework that may be further adapted to a number of related research questions.

Introducing two extensions of Schelling's segregation model
Andreas Flache Carlos A. de Matos Fernandes | Published Monday, January 25, 2021Schelling famously proposed an extremely simple but highly illustrative social mechanism to understand how strong ethnic segregation could arise in a world where individuals do not necessarily want it. Schelling’s simple computational model is the starting point for our extensions in which we build upon Wilensky’s original NetLogo implementation of this model. Our two NetLogo models can be best studied while reading our chapter “Agent-based Computational Models” (Flache and de Matos Fernandes, 2021). In the chapter, we propose 10 best practices to elucidate how agent-based models are a unique method for providing and analyzing formally precise, and empirically plausible mechanistic explanations of puzzling social phenomena, such as segregation, in the social world. Our chapter addresses in particular analytical sociologists who are new to ABMs.
In the first model (SegregationExtended), we build on Wilensky’s implementation of Schelling’s model which is available in NetLogo library (Wilensky, 1997). We considerably extend this model, allowing in particular to include larger neighborhoods and a population with four groups roughly resembling the ethnic composition of a contemporary large U.S. city. Further features added concern the possibility to include random noise, and the addition of a number of new outcome measures tuned to highlight macro-level implications of the segregation dynamics for different groups in the agent society.
In SegregationDiscreteChoice, we further modify the model incorporating in particular three new features: 1) heterogeneous preferences roughly based on empirical research categorizing agents into low, medium, and highly tolerant within each of the ethnic subgroups of the population, 2) we drop global thresholds (%-similar-wanted) and introduce instead a continuous individual-level single-peaked preference function for agents’ ideal neighborhood composition, and 3) we use a discrete choice model according to which agents probabilistically decide whether to move to a vacant spot or stay in the current spot by comparing the attractiveness of both locations based on the individual preference functions.
…

3D Urban Traffic Simulator (ABM) in Unity
Daniel Birks Sedar Olmez Obi Thompson Sargoni Alison Heppenstall Annabel Whipp Ed Manley | Published Friday, January 22, 2021 | Last modified Monday, March 22, 2021The Urban Traffic Simulator is an agent-based model developed in the Unity platform. The model allows the user to simulate several autonomous vehicles (AVs) and tune granular parameters such as vehicle downforce, adherence to speed limits, top speed in mph and mass. The model allows researchers to tune these parameters, run the simulator for a given period and export data from the model for analysis (an example is provided in Jupyter Notebook).
The data the model is currently able to output are the following:
…
Displaying 10 of 151 results C clear search