Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 49 results adaptation clear search

Simulating Climate Stress and Social Instability: An Agent-Based Model of Ecosystem Degradation and Violence in Coastal Communities
Jacopo A. Baggio hurtado-valdivieso | Published Sunday, April 12, 2026This model is an agent-based simulation designed to explore how climate-induced environmental degradation can contribute to the emergence of social violence in coastal communities that depend heavily on ecosystem services for their livelihoods. The model represents a coupled social–ecological system in which environmental shocks—such as sea level rise and marine ecosystem decline—affect local economic conditions, food security, and community stability.
Agents in the model represent individuals whose livelihoods depend on coastal ecosystems. Environmental degradation reduces ecosystem productivity and increases economic hardship, which can lead to the formation of grievances among agents. The model incorporates behavioral thresholds that determine how individuals respond to hardship and perceived injustice. Under certain conditions—particularly when institutional capacity and law enforcement effectiveness are limited—these grievances may escalate into violent behavior.
The simulation allows users to explore how different climate scenarios, levels of ecosystem degradation, livelihood dependence, and institutional responses influence the probability of social instability and violence. By modeling the interactions between environmental stress, socio-economic vulnerability, and governance capacity, the model provides a computational framework for examining potential pathways linking climate change and conflict in coastal social–ecological systems.
…
Peer reviewed Green Consumption Tipping Point
Mario | Published Thursday, February 26, 2026This model is a minimal agent-based model (ABM) of green consumption and market tipping dynamics in a stylised two-firm economy. It is designed as an existence proof to illustrate how weak individual preferences, when combined with habit formation, social influence, and firm price adaptation, can generate non-linear transitions (tipping points) in market outcomes.
The economy consists of:
1) Two firms, each supplying a differentiated consumption bundle that differs in its fixed green share (one relatively greener, one less green).
2) Many households, each consuming a unit mass per period and allocating consumption between the two firms.
…
Structural Violence and Neurobiological Adaptation: Modeling the Trajectory of Youth Outside of Care
masterpiece33330-prog | Published Thursday, November 27, 2025This study presents a System Dynamics (SD) model that explores the “trajectories of homelessness” among youth outside of the formal care system. Unlike traditional approaches that view runaway behavior as a discrete choice, this model reinterprets it as a neurobiological adaptation to chronic resource deprivation and systemic neglect.
The model incorporates key mechanisms such as ‘Allostatic Load’ accumulation, ‘PFC-Amygdala Switching’, and the ‘Iatrogenic Effects’ of shelter policies. It utilizes Monte Carlo simulations to demonstrate how structural factors create a “probabilistic vulnerability,” trapping youth in cycles of survival crime and isolation regardless of individual resilience.
The uploaded code includes a Python implementation of the model to ensure reproducibility of the stochastic analysis presented in the paper.
Behavioural model
Aulia Imania Sukma | Published Friday, November 07, 2025This repository serves as a design proof for agent-based modeling simulation in heat adaptation behavior. This model was developed as part of the UrbanAir project theme. This repository will be kept updated in the four-year timeline (2025 until 2029).
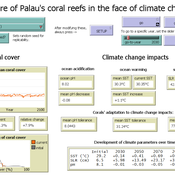
Development of coral reefs under climate change impacts and adaptation options
Nina Preußler | Published Friday, May 30, 2025This NetLogo model simulates how coral reefs around the islands of Palau would develop under different emission scenarios and with selected adaptation strategies. Reef health is indicated by coral cover (%) and is affected by four major climate change impacts: increasing sea surface temperature, sea level rise, ocean acidification, and more intense typhoons. The model differentiates between inner and outer reefs, with the former naturally adapted to warmer, more acidic waters. The simulation includes bleaching events and possible recovery. In addition, the user can choose between different coral transplantation strategies as well as regulate natural thermal adaptation rates.

Peer reviewed soslivestock model
Marco Janssen Irene Perez Ibarra Diego J. Soler-Navarro Alicia Tenza Peral | Published Wednesday, May 28, 2025 | Last modified Tuesday, June 10, 2025The purpose of this model is to analyze how different management strategies affect the wellbeing, sustainability and resilience of an extensive livestock system under scenarios of climate change and landscape configurations. For this purpose, it simulates one cattle farming system, in which agents (cattle) move through the space using resources (grass). Three farmer profiles are considered: 1) a subsistence farmer that emphasizes self-sufficiency and low costs with limited attention to herd management practices, 2) a commercial farmer focused on profit maximization through efficient production methods, and 3) an environmental farmer that prioritizes conservation of natural resources and animal welfare over profit maximization. These three farmer profiles share the same management strategies to adapt to climate and resource conditions, but differ in their goals and decision-making criteria for when, how, and whether to implement those strategies. This model is based on the SequiaBasalto model (Dieguez Cameroni et al. 2012, 2014, Bommel et al. 2014 and Morales et al. 2015), replicated in NetLogo by Soler-Navarro et al. (2023).
One year is 368 days. Seasons change every 92 days. Each step begins with the growth of grass as a function of climate and season. This is followed by updating the live weight of animals according to the grass height of their patch, and grass consumption, which is determined based on the updated live weight. Animals can be supplemented by the farmer in case of severe drought. After consumption, cows grow and reproduce, and a new grass height is calculated. This updated grass height value becomes the starting grass height for the next day. Cows then move to the next area with the highest grass height. After that, cattle prices are updated and cattle sales are held on the first day of fall. In the event of a severe drought, special sales are held. Finally, at the end of the day, the farm balance and the farmer’s effort are calculated.
Social Innovation Model
Jiin Jung | Published Monday, April 28, 2025This research aims to uncover the micro-mechanisms that drive the macro-level relationship between cultural tolerance and innovation. We focus on the indirect influence of minorities—specifically, workers with diverse domain expertise—within collaboration networks. We propose that minority influence from individuals with different expertise can serve as a key driver of organizational innovation, particularly in dynamic market environments, and that cultural tolerance is critical for enabling such minority-induced innovation. Our model demonstrates that seemingly conflicting empirical patterns between cultural tightness/looseness and innovation can emerge from the same underlying micro-mechanisms, depending on parameter values. A systematic simulation experiment revealed an optimal cultural configuration: a medium level of tolerance (t = 0.6) combined with low consistency (κ = 0.05) produced the fastest adaptation to abrupt market changes. These findings provide evidence that indirect minority influence is a core micro-mechanism linking cultural tolerance to innovation.
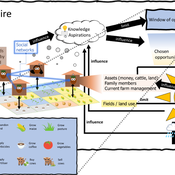
3spire: an agent-based model for exploring aspiration adaptation theory and its implications on smallholder farmers in Ethiopia
ateeuw Yue Dou Markus A Meyer Andrew Nelson | Published Sunday, February 16, 20253spire is an ABM where farming households make management decisions aimed at satisficing along the aspirational dimensions: food self-sufficiency, income, and leisure. Households decision outcomes depend on their social networks, knowledge, assets, household needs, past management, and climate/market trends
Agent-Based Model of Transhumant Decision-Making Processes in Senegal
Cheick Amed Diloma Gabriel TRAORE Etienne DELAY Alassane Bah Djibril Diop | Published Wednesday, July 03, 2024Sahelian transhumance is a type of socio-economic and environmental pastoral mobility. It involves the movement of herds from their terroir of origin (i.e., their original pastures) to one or more host terroirs, followed by a return to the terroir of origin. According to certain pastoralists, the mobility of herds is planned to prevent environmental degradation, given the continuous dependence of these herds on their environment. However, these herds emit Greenhouse Gases (GHGs) in the spaces they traverse. Given that GHGs contribute to global warming, our long-term objective is to quantify the GHGs emitted by Sahelian herds. The determination of these herds’ GHG emissions requires: (1) the artificial replication of the transhumance, and (2) precise knowledge of the space used during their transhumance.
This article presents the design of an artificial replication of the transhumance through an agent-based model named MSTRANS. MSTRANS determines the space used by transhumant herds, based on the decision-making process of Sahelian transhumants.
MSTRANS integrates a constrained multi-objective optimization problem and algorithms into an agent-based model. The constrained multi-objective optimization problem encapsulates the rationality and adaptability of pastoral strategies. Interactions between a transhumant and its socio-economic network are modeled using algorithms, diffusion processes, and within the multi-objective optimization problem. The dynamics of pastoral resources are formalized at various spatio-temporal scales using equations that are integrated into the algorithms.
The results of MSTRANS are validated using GPS data collected from transhumant herds in Senegal. MSTRANS results highlight the relevance of integrated models and constrained multi-objective optimization for modeling and monitoring the movements of transhumant herds in the Sahel. Now specialists in calculating greenhouse gas emissions have a reproducible and reusable tool for determining the space occupied by transhumant herds in a Sahelian country. In addition, decision-makers, pastoralists, veterinarians and traders have a reproducible and reusable tool to help them make environmental and socio-economic decisions.

Peer reviewed The Viability of the Social-Ecological Agroecosystem (ViSA) Spatial Agent-based Model
Mostafa Shaaban | Published Monday, March 25, 2024ViSA 2.0.0 is an updated version of ViSA 1.0.0 aiming at integrating empirical data of a new use case that is much smaller than in the first version to include field scale analysis. Further, the code of the model is simplified to make the model easier and faster. Some features from the previous version have been removed.
It simulates decision behaviors of different stakeholders showing demands for ecosystem services (ESS) in agricultural landscape. It investigates conditions and scenarios that can increase the supply of ecosystem services while keeping the viability of the social system by suggesting different mixes of initial unit utilities and decision rules.
Displaying 10 of 49 results adaptation clear search