Our mission is to help computational modelers develop, document, and share their computational models in accordance with community standards and good open science and software engineering practices. Model authors can publish their model source code in the Computational Model Library with narrative documentation as well as metadata that supports open science and emerging norms that facilitate software citation, computational reproducibility / frictionless reuse, and interoperability. Model authors can also request private peer review of their computational models. Models that pass peer review receive a DOI once published.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and feel free to contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
Displaying 10 of 1139 results for "Oto Hudec" clear search
Wolf-sheep predation Netlogo model, extended, with foresight
Guido Fioretti Andrea Policarpi | Published Wednesday, September 16, 2020 | Last modified Tuesday, April 13, 2021This model is an extension of the Netlogo Wolf-sheep predation model by U.Wilensky (1997). This extended model studies several different behavioural mechanisms that wolves and sheep could adopt in order to enhance their survivability, and their overall impact on global equilibrium of the system.
Activation Regimes in Opinion Dynamics
Meysam Alizadeh Claudio Cioffi-Revilla | Published Tuesday, September 01, 2015We compare the effect of four activation regimes by measuring the appropriate opinion clustering statistics and also the number of emergent extremists.
Institutional change
Abigail Sullivan | Published Friday, October 07, 2016 | Last modified Sunday, December 02, 2018This model builds on another model in this library (“diffusion of culture”).
High Standards Enhance Inequality in Idealized Labor Markets
Károly Takács | Published Tuesday, March 20, 2018Takács, K. and Squazzoni, F. 2015. High Standards Enhance Inequality in Idealized Labor Markets. Journal of Artificial Societies and Social Simulation, 18(4), 2, http://jasss.soc.surrey.ac.uk/18/4/2.html
We built a simple model of an idealized labor market, in which there is no objective difference in average quality between groups and hiring decisions are not biased in favor of any particular group. Our results show that inequality in employment emerges necessarily also in such idealized situations due to the limited supply of high quality individuals and asymmetric information. Inequalities are exacerbated when employers have high standards and keep only the best workers in house. We found that ambitious workers get higher quality jobs even if ambition does not correlate or even negatively correlates with internal quality. Our findings help to corroborate empirical findings on higher employment discrepancies in high rather than low status jobs.
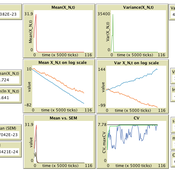
Population size limits the coefficient of variation in continuous traits affected by proportional copying error
Luke Premo | Published Thursday, June 18, 2020This version of the accumulated copying error (ACE) model is designed to address the following research question: how does finite population size (N) affect the coefficient of variation (CV) of a continuous cultural trait under the assumptions that the only source of copying error is visual perception error and that the continuous trait can take any positive value (i.e., it has no upper bound)? The model allows one to address this question while assuming the continuous trait is transmitted via vertical transmission, unbiased transmission, prestige biased transmission, mean conformist transmission, or median conformist transmission. By varying the parameter, p, one can also investigate the effect of population size under a mix of vertical and non-vertical transmission, whereby on average (1-p)N individuals learn via vertical transmission and pN individuals learn via either unbiased transmission, prestige biased transmission, mean conformist transmission, or median conformist transmission.
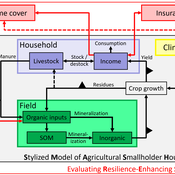
SMASH: Stylized Model of Agricultural Smallholder Households
Tim Williams | Published Tuesday, December 08, 2020The SMASH model is an agent-based model of rural smallholder households. It models households’ evolving income and wealth, which they earn through crop sales. Wealth is carried in the form of livestock, which are grazed on an external rangeland (exogenous) and can be bought/sold as investment/coping mechanisms. The model includes a stylized representation of soil nutrient dynamics, modeling the inflows and outflows of organic and inorganic nitrogen from each household’s field.
The model has been applied to assess the resilience-enhancing effects of two different farm-level adaptation strategies: legume cover cropping and crop insurance. These two strategies interact with the model through different mechanims - legume cover cropping through ecological mechanisms and crop insurance through financial mechanisms. The model can be used to investigate the short- and long-term effects of these strategies, as well as how they may differently benefit different types of household.
Confirmation Bias improves Performance in a Signal Detection Task and evolves in an Evolutionary Algorithm
Michael Vogrin | Published Monday, May 08, 2023Confirmation Bias is usually seen as a flaw of the human mind. However, in some tasks, it may also increase performance. Here, agents are confronted with a number of binary Signals (A, or B). They have a base detection rate, e.g. 50%, and after they detected one signal, they get biased towards this type of signal. This means, that they observe that kind of signal a bit better, and the other signal a bit worse. This is moderated by a variable called “bias_effect”, e.g. 10%. So an agent who detects A first, gets biased towards A and then improves its chance to detect A-signals by 10%. Thus, this agent detects A-Signals with the probability of 50%+10% = 60% and detects B-Signals with the probability of 50%-10% = 40%.
Given such a framework, agents that have the ability to be biased have better results in most of the scenarios.
Opinion Leaders' Role in Innovation Diffusion
Peter Van Eck | Published Wednesday, March 10, 2010 | Last modified Saturday, April 27, 2013This model is used to investigate the role of opinion leader. More specifically: the influence of ‘innovative behavior’, ‘weigth of normative influence’, ‘better product judgment’, ‘number of opinion
Memetic Exploration of Demand
rolanmd | Published Monday, August 09, 2010 | Last modified Saturday, April 27, 2013In this presentation, we use the concept of meme to explore evolution of demand.
Seeding for information transmission in social networks
Beatrice Nöldeke Ulrike Grote Etti Winter | Published Tuesday, November 03, 2020This model simulates different seeding strategies for information diffusion in a social network adjusted to a case study area in rural Zambia. It systematically evaluates different criteria for seed selection (centrality measures and hierarchy), number of seeds, and interaction effects between seed selection criteria and set size.
Displaying 10 of 1139 results for "Oto Hudec" clear search