About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 2 of 2 results scientific value clear search
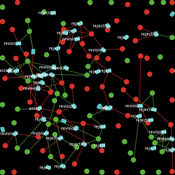
The PRIF Model
Davide Secchi | Published Friday, November 08, 2019This model takes into consideration Peer Reviewing under the influence of Impact Factor (PRIF) and it has the purpose to explore whether the infamous metric affects assessment of papers under review. The idea is to consider to types of reviewers, those who are agnostic towards IF (IU1) and those that believe that it is a measure of journal (and article) quality (IU2). This perception is somehow reflected in the evaluation, because the perceived scientific value of a paper becomes a function of the journal in which an article has been submitted. Various mechanisms to update reviewer preferences are also implemented.
Perceived Scientific Value and Impact Factor
Davide Secchi Stephen J Cowley | Published Wednesday, April 12, 2017 | Last modified Monday, January 29, 2018The model explores the impact of journal metrics (e.g., the notorious impact factor) on the perception that academics have of an article’s scientific value.