About the CoMSES Model Library more info
Our mission is to help computational modelers at all levels engage in the establishment and adoption of community standards and good practices for developing and sharing computational models. Model authors can freely publish their model source code in the Computational Model Library alongside narrative documentation, open science metadata, and other emerging open science norms that facilitate software citation, reproducibility, interoperability, and reuse. Model authors can also request peer review of their computational models to receive a DOI.
All users of models published in the library must cite model authors when they use and benefit from their code.
Please check out our model publishing tutorial and contact us if you have any questions or concerns about publishing your model(s) in the Computational Model Library.
We also maintain a curated database of over 7500 publications of agent-based and individual based models with additional detailed metadata on availability of code and bibliometric information on the landscape of ABM/IBM publications that we welcome you to explore.
Displaying 10 of 912 results for "Coen Van Wagenberg" clear search
Agent-based model of sexual partnership
Andrea Knittel | Published Monday, December 05, 2011 | Last modified Saturday, April 27, 2013In this model agents meet, evaluate one another, decide whether or not to date, if and when to become sexual partners, and when to break up.
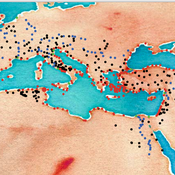
Roman Amphora reuse
Tom Brughmans | Published Wednesday, August 07, 2019 | Last modified Wednesday, March 15, 2023UPDATE in V1.1.0: missing input data files added; relative paths to input data files changed to “../data/FILENAME”
A model that allows for representing key theories of Roman amphora reuse, to explore the differences in the distribution of amphorae, re-used amphorae and their contents.
This model generates simulated distributions of prime-use amphorae, primeuse contents (e.g. olive oil) and reused amphorae. These simulated distributions will differ between experiments depending on the experiment’s variable settings representing the tested theory: variations in the probability of reuse, the supply volume, the probability of reuse at ports. What we are interested in teasing out is what the effect is of each theory on the simulated amphora distributions.
…
Last Mile Commuter Behavior Model
Dean Massey Moira Zellner Yoram Shiftan Jonathan Levine Maria Arquero | Published Friday, November 07, 2014 | Last modified Friday, November 07, 2014We represent commuters and their preferences for transportation cost, time and safety. Agents assess their options via their preferences, their environment, and the modes available. The model has policy levers to test impact on last-mile problem.
This is a social trust model for investigating the social relationships and social networks in the real world and in social media.
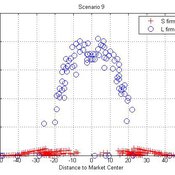
Micro-level Adaptation, Macro-level Selection, and the Dynamics of Market Partitioning
César García-Díaz | Published Monday, October 19, 2015 | Last modified Monday, October 19, 2015This model simulates the emergence of a dual market structure from firm-level interaction. Firms are profit-seeking, and demand is represented by a unimodal distribution of consumers along a set of taste positions.
Peer reviewed BAMERS: Macroeconomic effect of extortion
Alejandro Platas López Alejandro Guerra-Hernández | Published Monday, March 23, 2020 | Last modified Sunday, July 26, 2020Inspired by the European project called GLODERS that thoroughly analyzed the dynamics of extortive systems, Bottom-up Adaptive Macroeconomics with Extortion (BAMERS) is a model to study the effect of extortion on macroeconomic aggregates through simulation. This methodology is adequate to cope with the scarce data associated to the hidden nature of extortion, which difficults analytical approaches. As a first approximation, a generic economy with healthy macroeconomics signals is modeled and validated, i.e., moderate inflation, as well as a reasonable unemployment rate are warranteed. Such economy is used to study the effect of extortion in such signals. It is worth mentioning that, as far as is known, there is no work that analyzes the effects of extortion on macroeconomic indicators from an agent-based perspective. Our results show that there is significant effects on some macroeconomics indicators, in particular, propensity to consume has a direct linear relationship with extortion, indicating that people become poorer, which impacts both the Gini Index and inflation. The GDP shows a marked contraction with the slightest presence of extortion in the economic system.
User Guide and Templates for RAT-RS (a reporting standard for improving the documentation of data use in agent-based modelling)
Melania Borit Edmund Chattoe-Brown Peer-Olaf Siebers Sebastian Achter | Published Saturday, March 12, 2022The Rigor and Transparency Reporting Standard (RAT-RS) is a tool to improve the documentation of data use in Agent-Based Modelling. Following the development of reporting standards for models themselves, attention to empirical models has now reached a stage where these standards need to take equally effective account of data use (which until now has tended to be an afterthought to model description). It is particularly important that a standard should allow the reporting of the different uses to which data may be put (specification, calibration and validation), but also that it should be compatible with the integration of different kinds of data (for example statistical, qualitative, ethnographic and experimental) sometimes known as mixed methods research.
For the full details on the RAT-RS, please refer to the related publication “RAT-RS: A Reporting Standard for Improving the Documentation of Data Use in Agent-Based Modelling” (http://dx.doi.org/10.1080/13645579.2022.2049511).
Here we provide supplementary material for this article, consisting of a RAT-RS user guide and RAT-RS templates.
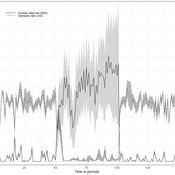
A basic macroeconomic agent-based model for analyzing monetary regime shifts
Oliver Reinhardt Florian Peters Doris Neuberger Adelinde Uhrmacher | Published Tuesday, May 03, 2022In macroeconomics, an emerging discussion of alternative monetary systems addresses the dimensions of systemic risk in advanced financial systems. Monetary regime changes with the aim of achieving a more sustainable financial system have already been discussed in several European parliaments and were the subject of a referendum in Switzerland. However, their effectiveness and efficacy concerning macro-financial stability are not well-known. This paper introduces a macroeconomic agent-based model (MABM) in a novel simulation environment to simulate the current monetary system, which may serve as a basis to implement and analyze monetary regime shifts. In this context, the monetary system affects the lending potential of banks and might impact the dynamics of financial crises. MABMs are predestined to replicate emergent financial crisis dynamics, analyze institutional changes within a financial system, and thus measure macro-financial stability. The used simulation environment makes the model more accessible and facilitates exploring the impact of different hypotheses and mechanisms in a less complex way. The model replicates a wide range of stylized economic facts, including simplifying assumptions to reduce model complexity.
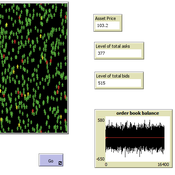
Peer reviewed A financial market with zero intelligence agents
edgarkp | Published Wednesday, March 27, 2024The model’s aim is to represent the price dynamics under very simple market conditions, given the values adopted by the user for the model parameters. We suppose the market of a financial asset contains agents on the hypothesis they have zero-intelligence. In each period, a certain amount of agents are randomly selected to participate to the market. Each of these agents decides, in a equiprobable way, between proposing to make a transaction (talk = 1) or not (talk = 0). Again in an equiprobable way, each participating agent decides to speak on the supply (ask) or the demand side (bid) of the market, and proposes a volume of assets, where this number is drawn randomly from a uniform distribution. The granularity depends on various factors, including market conventions, the type of assets or goods being traded, and regulatory requirements. In some markets, high granularity is essential to capture small price movements accurately, while in others, coarser granularity is sufficient due to the nature of the assets or goods being traded
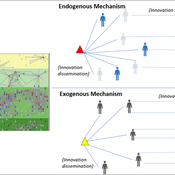
Peer reviewed Modelling Agricultural Innovations as a Social-Ecological Phenomenon
Maja Schlüter Udita Sanga | Published Thursday, November 17, 2022The goal of the AG-Innovation agent-based model is to explore and compare the effects of two alternative mechanisms of innovation development and diffusion (exogenous, linear and endogenous, non-linear) on emergent properties of food and income distribution and adoption rates of different innovations. The model also assesses the range of conditions under which these two alternative mechanisms would be effective in improving food security and income inequality outcomes. Our modelling questions were: i) How do cross-scalar social-ecological interactions within agricultural innovation systems affect system outcomes of food security and income inequality? ii) Do foreign aid-driven exogenous innovation perpetuate income inequality and food insecurity and if so, under which conditions? iii) Do community-driven endogenous innovations improve food security and income inequality and if so, under which conditions? The Ag-Innovation model is intended to serve as a thinking tool for for the development and testing of hypotheses, generating an understanding of the behavior of agricultural innovation systems, and identifying conditions under which alternated innovation mechanisms would improve food security and income inequality outcomes.
Displaying 10 of 912 results for "Coen Van Wagenberg" clear search